Technical Writings
- C++ Concurrency Book
- Articles and Publications
- Conference Presentations
- Recent Blog Entries
- Multithreading Blog Entries
- C++ Blog Entries
Subscribe to Blog
Blog Archives
Blog Archive
Rvalue References and Perfect Forwarding in C++0x
Wednesday, 03 December 2008
One of the new features
in C++0x
is the rvalue reference. Whereas the a "normal" lvalue
reference is declared with a single ampersand &,
an rvalue reference is declared with two
ampersands: &&. The key difference is of course
that an rvalue reference can bind to an rvalue, whereas a
non-const lvalue reference cannot. This is primarily used
to support move semantics for expensive-to-copy objects:
class X
{
std::vector<double> data;
public:
X():
data(100000) // lots of data
{}
X(X const& other): // copy constructor
data(other.data) // duplicate all that data
{}
X(X&& other): // move constructor
data(std::move(other.data)) // move the data: no copies
{}
X& operator=(X const& other) // copy-assignment
{
data=other.data; // copy all the data
return *this;
}
X& operator=(X && other) // move-assignment
{
data=std::move(other.data); // move the data: no copies
return *this;
}
};
X make_x(); // build an X with some data
int main()
{
X x1;
X x2(x1); // copy
X x3(std::move(x1)); // move: x1 no longer has any data
x1=make_x(); // return value is an rvalue, so move rather than copy
}
Though move semantics are powerful, rvalue references offer more than that.
Perfect Forwarding
When you combine rvalue references with function templates you get an interesting interaction: if the type of a function parameter is an rvalue reference to a template type parameter then the type parameter is deduce to be an lvalue reference if an lvalue is passed, and a plain type otherwise. This sounds complicated, so lets look at an example:
template<typename T>
void f(T&& t);
int main()
{
X x;
f(x); // 1
f(X()); // 2
}
The function template f meets our criterion above, so
in the call f(x) at the line marked "1", the template
parameter T is deduced to be X&,
whereas in the line marked "2", the supplied parameter is an rvalue
(because it's a temporary), so T is deduced to
be X.
Why is this useful? Well, it means that a function template can
pass its arguments through to another function whilst retaining the
lvalue/rvalue nature of the function arguments by
using std::forward. This is called "perfect
forwarding", avoids excessive copying, and avoids the template
author having to write multiple overloads for lvalue and rvalue
references. Let's look at an example:
void g(X&& t); // A
void g(X& t); // B
template<typename T>
void f(T&& t)
{
g(std::forward<T>(t));
}
void h(X&& t)
{
g(t);
}
int main()
{
X x;
f(x); // 1
f(X()); // 2
h(x);
h(X()); // 3
}
This time our function f forwards its argument to a
function g which is overloaded for lvalue and rvalue
references to an X object. g will
therefore accept lvalues and rvalues alike, but overload resolution
will bind to a different function in each case.
At line "1", we pass a named X object
to f, so T is deduced to be an lvalue
reference: X&, as we saw above. When T
is an lvalue reference, std::forward<T> is a
no-op: it just returns its argument. We therefore call the overload
of g that takes an lvalue reference (line B).
At line "2", we pass a temporary to f,
so T is just plain X. In this
case, std::forward<T>(t) is equivalent
to static_cast<T&&>(t): it ensures that
the argument is forwarded as an rvalue reference. This means that
the overload of g that takes an rvalue reference is
selected (line A).
This is called perfect forwarding because the same
overload of g is selected as if the same argument was
supplied to g directly. It is essential for library
features such as std::function
and std::thread which pass arguments to another (user
supplied) function.
Note that this is unique to template functions: we can't do this
with a non-template function such as h, since we don't
know whether the supplied argument is an lvalue or an rvalue. Within
a function that takes its arguments as rvalue references, the named
parameter is treated as an lvalue reference. Consequently the call
to g(t) from h always calls the lvalue
overload. If we changed the call
to g(std::forward<X>(t)) then it would always
call the rvalue-reference overload. The only way to do this with
"normal" functions is to create two overloads: one for lvalues and
one for rvalues.
Now imagine that we remove the overload of g for
rvalue references (delete line A). Calling f with an
rvalue (line 2) will now fail to compile because you can't
call g with an rvalue. On the other hand, our call
to h with an rvalue (line 3) will still
compile however, since it always calls the lvalue-reference
overload of g. This can lead to interesting problems
if g stores the reference for later use.
Further Reading
For more information, I suggest reading the accepted rvalue reference paper and "A Brief Introduction to Rvalue References", as well as the current C++0x working draft.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: rvalue reference, cplusplus, C++0x, forwarding
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Memory Models and Synchronization
Monday, 24 November 2008
I have read a couple of posts on memory models over the couple of weeks: one from Jeremy Manson on What Volatile Means in Java, and one from Bartosz Milewski entitled Who ordered sequential consistency?. Both of these cover a Sequentially Consistent memory model — in Jeremy's case because sequential consistency is required by the Java Memory Model, and in Bartosz' case because he's explaining what it means to be sequentially consistent, and why we would want that.
In a sequentially consistent memory model, there is a single total order of all atomic operations which is the same across all processors in the system. You might not know what the order is in advance, and it may change from execution to execution, but there is always a total order.
This is the default for the new C++0x atomics, and required for
Java's volatile, for good reason — it is
considerably easier to reason about the behaviour of code that uses
sequentially consistent orderings than code that uses a more relaxed
ordering.
The thing is, C++0x atomics are only sequentially consistent by default — they also support more relaxed orderings.
Relaxed Atomics and Inconsistent Orderings
I briefly touched on the properties of relaxed atomic operations in my presentation on The Future of Concurrency in C++ at ACCU 2008 (see the slides). The key point is that relaxed operations are unordered. Consider this simple example with two threads:
#include <thread>
#include <cstdatomic>
std::atomic<int> x(0),y(0);
void thread1()
{
x.store(1,std::memory_order_relaxed);
y.store(1,std::memory_order_relaxed);
}
void thread2()
{
int a=y.load(std::memory_order_relaxed);
int b=x.load(std::memory_order_relaxed);
if(a==1)
assert(b==1);
}
std::thread t1(thread1);
std::thread t2(thread2);
All the atomic operations here are using
memory_order_relaxed, so there is no enforced
ordering. Therefore, even though thread1 stores
x before y, there is no guarantee that the
writes will reach thread2 in that order: even if
a==1 (implying thread2 has seen the result
of the store to y), there is no guarantee that
b==1, and the assert may fire.
If we add more variables and more threads, then each thread may see a different order for the writes. Some of the results can be even more surprising than that, even with two threads. The C++0x working paper features the following example:
void thread1()
{
int r1=y.load(std::memory_order_relaxed);
x.store(r1,std::memory_order_relaxed);
}
void thread2()
{
int r2=x.load(std::memory_order_relaxed);
y.store(42,std::memory_order_relaxed);
assert(r2==42);
}
There's no ordering between threads, so thread1 might
see the store to y from thread2, and thus
store the value 42 in x. The fun part comes because the
load from x in thread2 can be reordered
after everything else (even the store that occurs after it in the same
thread) and thus load the value 42! Of course, there's no guarantee
about this, so the assert may or may not fire — we
just don't know.
Acquire and Release Ordering
Now you've seen quite how scary life can be with relaxed operations, it's time to look at acquire and release ordering. This provides pairwise synchronization between threads — the thread doing a load sees all the changes made before the corresponding store in another thread. Most of the time, this is actually all you need — you still get the "two cones" effect described in Jeremy's blog post.
With acquire-release ordering, independent reads of variables written independently can still give different orders in different threads, so if you do that sort of thing then you still need to think carefully. e.g.
std::atomicx(0),y(0); void thread1() { x.store(1,std::memory_order_release); } void thread2() { y.store(1,std::memory_order_release); } void thread3() { int a=x.load(std::memory_order_acquire); int b=y.load(std::memory_order_acquire); } void thread4() { int c=x.load(std::memory_order_acquire); int d=y.load(std::memory_order_acquire); }
Yes, thread3 and thread4 have the same
code, but I separated them out to make it clear we've got two separate
threads. In this example, the stores are on separate threads, so there
is no ordering between them. Consequently the reader threads may see
the writes in either order, and you might get a==1 and
b==0 or vice versa, or both 1 or both 0. The fun part is
that the two reader threads might see opposite
orders, so you have a==1 and b==0, but
c==0 and d==1! With sequentially consistent
code, both threads must see consistent orderings, so this would be
disallowed.
Summary
The details of relaxed memory models can be confusing, even for experts. If you're writing code that uses bare atomics, stick to sequential consistency until you can demonstrate that this is causing an undesirable impact on performance.
There's a lot more to the C++0x memory model and atomic operations than I can cover in a blog post — I go into much more depth in the chapter on atomics in my book.
Posted by Anthony Williams
[/ threading /] permanent link
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
First Review of C++ Concurrency in Action
Monday, 24 November 2008
A Dean Michael Berris has just published the first review of C++ Concurrency in Action that I've seen over on his blog. Thanks for your kind words, Dean!
C++ Concurrency in Action is not yet finished, but you can buy a copy now under the Manning Early Access Program and you'll get a PDF with the current chapters (plus updates as I write new chapters) and either a PDF or hard copy of the book (your choice) when it's finished.
Posted by Anthony Williams
[/ news /] permanent link
Tags: review, C++, cplusplus, concurrency, book
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Deadlock Detection with just::thread
Wednesday, 12 November 2008
One of the biggest problems with multithreaded programming is the
possibility of deadlocks. In the excerpt from my
book published over at codeguru.com (Deadlock:
The problem and a solution) I discuss various ways of dealing with
deadlock, such as using std::lock when acquiring multiple
locks at once and acquiring locks in a fixed order.
Following such guidelines requires discipline, especially on large
code bases, and occasionally we all slip up. This is where the
deadlock detection mode of the
just::thread library comes in: if you compile your
code with deadlock detection enabled then if a deadlock occurs the
library will display a stack trace of the deadlock threads
and the locations at which the synchronization
objects involved in the deadlock were locked.
Let's look at the following simple code for an example.
#include <thread>
#include <mutex>
#include <iostream>
std::mutex io_mutex;
void thread_func()
{
std::lock_guard<std::mutex> lk(io_mutex);
std::cout<<"Hello from thread_func"<<std::endl;
}
int main()
{
std::thread t(thread_func);
std::lock_guard<std::mutex> lk(io_mutex);
std::cout<<"Hello from main thread"<<std::endl;
t.join();
return 0;
}
Now, it is obvious just from looking at the code that there's a
potential deadlock here: the main thread holds the lock on
io_mutex across the call to
t.join(). Therefore, if the main thread manages to lock
the io_mutex before the new thread does then the program
will deadlock: the main thread is waiting for thread_func
to complete, but thread_func is blocked on the
io_mutex, which is held by the main thread!
Compile the code and run it a few times: eventually you should hit the deadlock. In this case, the program will output "Hello from main thread" and then hang. The only way out is to kill the program.
Now compile the program again, but this time with
_JUST_THREAD_DEADLOCK_CHECK defined — you can
either define this in your project settings, or define it in the first
line of the program with #define. It must be defined
before any of the thread library headers are included
in order to take effect. This time the program doesn't hang —
instead it displays a message box with the title "Deadlock Detected!"
looking similar to the following:
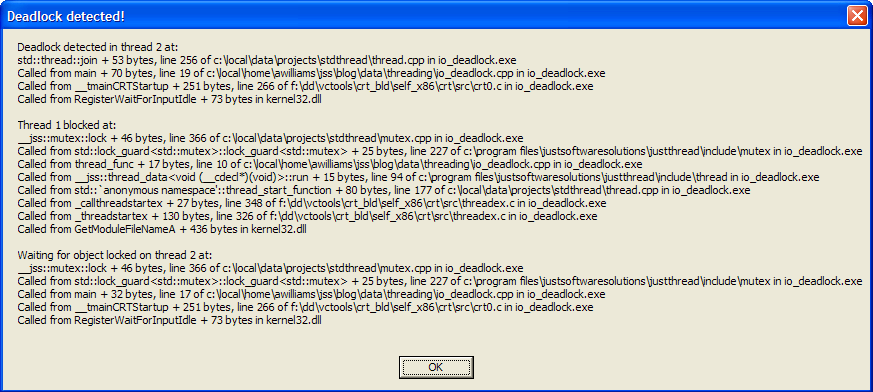
Of course, you need to have debug symbols for your executable to get meaningful stack traces.
Anyway, this message box shows three stack traces. The first is
labelled "Deadlock detected in thread 2 at:", and tells us that the
deadlock was found in the call to std::thread::join from
main, on line 19 of our source file
(io_deadlock.cpp). Now, it's important to note that "line 19" is
actually where execution will resume when join returns
rather than the call site, so in this case the call to
join is on line 18. If the next statement was also on
line 18, the stack would report line 18 here.
The next stack trace is labelled "Thread 1 blocked at:", and tells
us where the thread we're trying to join with is blocked. In this
case, it's blocked in the call to mutex::lock from the
std::lock_guard constructor called from
thread_func returning to line 10 of our source file (the
constructor is on line 9).
The final stack trace completes the circle by telling us where that
mutex was locked. In this case the label says "Waiting for object
locked on thread 2 at:", and the stack trace tells us it was the
std::lock_guard constructor in main
returning to line 17 of our source file.
This is all the information we need to see the deadlock in this case, but in more complex cases we might need to go further up the call stack, particularly if the deadlock occurs in a function called from lots of different threads, or the mutex being used in the function depends on its parameters.
The just::thread deadlock
detection can help there too: if you're running the application from
within the IDE, or you've got a Just-in-Time debugger installed then
the application will now break into the debugger. You can then use the
full capabilities of your debugger to examine the state of the
application when the deadlock occurred.
Try It Out
You can download sample Visual C++ Express 2008 project for this
example, which you can use with our just::thread
implementation of the new C++0x thread library. The code should also
work with g++.
just::thread
doesn't just work with Microsoft Visual Studio 2008 — it's also
available for g++ 4.3 on Ubuntu Linux. Get your copy
today and try out the deadlock detection feature
risk free with our 30-day money-back guarantee.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: multithreading, deadlock, c++
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Detect Deadlocks with just::thread C++0x Thread Library Beta V0.2
Saturday, 01 November 2008
I am pleased to announce that the second beta of just::thread, our C++0x Thread Library is
available, which now features deadlock detection for uses of
std::mutex. You can sign up at the just::thread Support
forum to download the beta or send an email to beta@stdthread.co.uk.
The just::thread library is a complete implementation
of the new C++0x thread library as per the current
C++0x working paper. Features include:
std::threadfor launching threads.- Mutexes and condition variables.
std::promise,std::packaged_task,std::unique_futureandstd::shared_futurefor transferring data between threads.- Support for the new
std::chronotime interface for sleeping and timeouts on locks and waits. - Atomic operations with
std::atomic. - Support for
std::exception_ptrfor transferring exceptions between threads. - New in beta 0.2: support for detecting deadlocks with
std::mutex
The library works with Microsoft Visual Studio 2008 or Microsoft Visual C++ 2008 Express for 32-bit Windows. Don't wait for a full C++0x compiler: start using the C++0x thread library today.
Sign up at the just::thread Support forum to download the beta.
Posted by Anthony Williams
[/ news /] permanent link
Tags: multithreading, concurrency, C++0x
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
just::thread C++0x Thread Library Beta V0.1 Released
Thursday, 16 October 2008
Update: just::thread was released on 8th January 2009. The just::thread C++0x thread library is currently available for purchase for Microsoft Visual Studio 2005, 2008 and 2010 for Windows and gcc 4.3, 4.4 and 4.5 for x86 Ubuntu Linux.
I am pleased to announce that just::thread, our C++0x Thread Library is now available as a beta release. You can sign up at the just::thread Support forum to download the beta or send an email to beta@stdthread.co.uk.
Currently, it only works with Microsoft Visual Studio 2008 or Microsoft Visual C++ 2008 Express for 32-bit Windows, though support for other compilers and platforms is in the pipeline.
Though there are a couple of limitations (such as the number of
arguments that can be supplied to a thread function, and the lack of
custom allocator support for std::promise), it is a
complete implementation of the new C++0x thread library as per the
current
C++0x working paper. Features include:
std::threadfor launching threads.- Mutexes and condition variables.
std::promise,std::packaged_task,std::unique_futureandstd::shared_futurefor transferring data between threads.- Support for the new
std::chronotime interface for sleeping and timeouts on locks and waits. - Atomic operations with
std::atomic. - Support for
std::exception_ptrfor transferring exceptions between threads.
Please sign up and download the beta today. The library should be going on sale by the end of November.
Please report bugs on the just::thread Support Forum or email to beta@stdthread.co.uk.
Posted by Anthony Williams
[/ news /] permanent link
Tags: multithreading, concurrency, C++0x
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
October 2008 C++ Standards Committee Mailing - New C++0x Working Paper, More Concurrency Papers Approved
Wednesday, 08 October 2008
The October 2008 mailing for the C++ Standards Committee was published today. This is a really important mailing, as it contains the latest edition of the C++0x Working Draft, which was put out as a formal Committee Draft at the September 2008 meeting. This means it is up for formal National Body voting and comments, and could in principle be the text of C++0x. Of course, there are still many issues with the draft and it will not be approved as-is, but it is "feature complete": if a feature is not in this draft it will not be in C++0x. The committee intends to fix the issues and have a final draft ready by this time next year.
Concurrency Papers
As usual, there's a number of concurrency-related papers that have been incorporated into the working draft. Some of these are from this mailing, and some from prior mailings. Let's take a look at each in turn:
- N2752: Proposed Text for Bidirectional Fences
- This paper modifies the wording for the use of fences in C++0x. It
is a new revision of N2731:
Proposed Text for Bidirectional Fences, and is the version voted
into the working paper. Now this paper has been accepted, fences are
no longer tied to specific atomic variables, but are represented by
the free functions
std::atomic_thread_fence()andstd::atomic_signal_fence(). This brings C++0x more in line with current CPU instruction sets, where fences are generally separate instructions with no associated object.std::atomic_signal_fence()just restricts the compiler's freedom to reorder variable accesses, whereasstd::atomic_thread_fence()will typically also cause the compiler to emit the specific synchronization instructions necessary to enforce the desired memory ordering. - N2782: C++ Data-Dependency Ordering: Function Annotation
- This is a revision of N2643:
C++ Data-Dependency Ordering: Function Annotation, and is the
final version voted in to the working paper. It allows functions to be
annotated with
[[carries_dependency]](using the just-accepted attributes proposal) on their parameters and return value. This can allow implementations to better-optimize code that usesstd::memory_order_consumememory ordering. - N2783: Collected Issues with Atomics
- This paper resolves LWG issues 818, 845, 846 and 864. This rewords
the descriptions of the memory ordering values to make it clear what
they mean, removes the
explicitqualification on thestd::atomic_xxxconstructors to allow implicit conversion on construction (and thus allow aggregate-style initialization), and adds simple definitions of the constructors for the atomic types (which were omitted by accident). - N2668: Concurrency Modifications to Basic String
- This has been under discussion for a while, but was finally
approved at the September meeting. The changes in this paper ensure
that it is safe for two threads to access the same
std::stringobject at the same time, provided they both perform only read operations. They also ensure that copying a string object and then modifying that copy is safe, even if another thread is accessing the original. This essentially disallows copy-on-write implementations since the benefits are now severely limited. - N2748: Strong Compare and Exchange
- This paper was in the previous mailing, and has now been
approved. In the previous working paper, the atomic
compare_exchangefunctions were allowed to fail "spuriously" even when the value of the object was equal to the comparand. This allows efficient implementation on a wider variety of platforms than otherwise, but also requires almost all uses ofcompare_exchangeto be put in a loop. Now this paper has been accepted, instead we provide two variants:compare_exchange_weakandcompare_exchange_strong. The weak variant allows spurious failure, whereas the strong variant is not allowed to fail spuriously. On architectures which provide the strong variant by default (such as x86) this would remove the need for a loop in some cases. - N2760: Input/Output Library Thread Safety
- This paper clarifies that unsynchronized access to I/O streams
from multiple threads is a data race. For most streams this means the
user is responsible for providing this synchronization. However, for
the standard stream objects (
std::cin,std::cout,std::cerrand friends) such external synchronization is only necessary if the user has calledstd::ios_base::sync_with_stdio(false). - N2775: Small library thread-safety revisions
- This short paper clarifies that the standard library functions may only access the data and call the functions that they are specified to do. This makes it easier to identify and eliminate potential data races when using standard library functions.
- N2671: An Asynchronous Future Value: Proposed Wording
- Futures are finally in C++0x! This paper from the June 2008
mailing gives us
std::unique_future<>,std::shared_future<>andstd::promise<>, which can be used for transferring the results of operations safely between threads. - N2709: Packaging Tasks for Asynchronous Execution
- Packaged Tasks are also in C++0x! This is my paper from the July
2008 mailing, which is the counterpart to N2671. A
std::packaged_task<F>is very similar to astd::function<F>except that rather than returning the result directly when it is invoked, the result is stored in the associated futures. This makes it easy to spawn functions with return values on threads, and provides a building block for thread pools.
Other Changes
The biggest change to the C++0x working paper is of course the acceptance of Concepts. There necessary changes are spread over a staggering 14 Concepts-related papers, all of which were voted in to the working draft at the September 2008 meeting.
C++0x now also has support for user-defined literals (N2765:
User-defined Literals (aka. Extensible Literals (revision 5))),
for default values of non-static data members to be
defined in the class definition (N2756:
Non-static data member initializers), and forward declaration of
enums (N2764:
Forward declaration of enumerations (rev. 3)).
Get Involved: Comment on the C++0x Draft
Please read the latest C++0x Working Draft and comment on it. If you post comments on this blog entry I'll see that the committee gets to see them, but I strongly urge you to get involved with your National Body: the only changes allowed to C++0x now are in response to official National Body comments. If you're in the UK, contact me and I'll put you in touch with the relevant people on the BSI panel.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: C++0x, C++, standards, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
"Deadlock: The Problem and a Solution" Book Excerpt Online
Wednesday, 01 October 2008
An excerpt from my book C++ Concurrency in Action
has been published on CodeGuru. Deadlock:
the Problem and a Solution describes what deadlock is and how the
std::lock() function can be used to avoid it where
multiple locks can be acquired at once. There are also some simple
guidelines for avoiding deadlock in the first place.
The C++0x library facilities mentioned in the article
(std::mutex, std::lock(),
std::lock_guard and std::unique_lock) are
all available from the Boost
Thread Library in release 1.36.0 and later.
Posted by Anthony Williams
[/ news /] permanent link
Tags: multithreading, c++, deadlock, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Implementing a Thread-Safe Queue using Condition Variables (Updated)
Tuesday, 16 September 2008
One problem that comes up time and again with multi-threaded code is how to transfer data from one thread to another. For example, one common way to parallelize a serial algorithm is to split it into independent chunks and make a pipeline — each stage in the pipeline can be run on a separate thread, and each stage adds the data to the input queue for the next stage when it's done. For this to work properly, the input queue needs to be written so that data can safely be added by one thread and removed by another thread without corrupting the data structure.
Basic Thread Safety with a Mutex
The simplest way of doing this is just to put wrap a non-thread-safe queue, and protect it with a mutex (the examples use the types and functions from the upcoming 1.35 release of Boost):
template<typename Data>
class concurrent_queue
{
private:
std::queue<Data> the_queue;
mutable boost::mutex the_mutex;
public:
void push(const Data& data)
{
boost::mutex::scoped_lock lock(the_mutex);
the_queue.push(data);
}
bool empty() const
{
boost::mutex::scoped_lock lock(the_mutex);
return the_queue.empty();
}
Data& front()
{
boost::mutex::scoped_lock lock(the_mutex);
return the_queue.front();
}
Data const& front() const
{
boost::mutex::scoped_lock lock(the_mutex);
return the_queue.front();
}
void pop()
{
boost::mutex::scoped_lock lock(the_mutex);
the_queue.pop();
}
};
This design is subject to race conditions between calls to empty, front and pop if there
is more than one thread removing items from the queue, but in a single-consumer system (as being discussed here), this is not a
problem. There is, however, a downside to such a simple implementation: if your pipeline stages are running on separate threads,
they likely have nothing to do if the queue is empty, so they end up with a wait loop:
while(some_queue.empty())
{
boost::this_thread::sleep(boost::posix_time::milliseconds(50));
}
Though the sleep avoids the high CPU consumption of a direct busy wait, there are still some obvious downsides to
this formulation. Firstly, the thread has to wake every 50ms or so (or whatever the sleep period is) in order to lock the mutex,
check the queue, and unlock the mutex, forcing a context switch. Secondly, the sleep period imposes a limit on how fast the thread
can respond to data being added to the queue — if the data is added just before the call to sleep, the thread
will wait at least 50ms before checking for data. On average, the thread will only respond to data after about half the sleep time
(25ms here).
Waiting with a Condition Variable
As an alternative to continuously polling the state of the queue, the sleep in the wait loop can be replaced with a condition
variable wait. If the condition variable is notified in push when data is added to an empty queue, then the waiting
thread will wake. This requires access to the mutex used to protect the queue, so needs to be implemented as a member function of
concurrent_queue:
template<typename Data>
class concurrent_queue
{
private:
boost::condition_variable the_condition_variable;
public:
void wait_for_data()
{
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
the_condition_variable.wait(lock);
}
}
void push(Data const& data)
{
boost::mutex::scoped_lock lock(the_mutex);
bool const was_empty=the_queue.empty();
the_queue.push(data);
if(was_empty)
{
the_condition_variable.notify_one();
}
}
// rest as before
};
There are three important things to note here. Firstly, the lock variable is passed as a parameter to
wait — this allows the condition variable implementation to atomically unlock the mutex and add the thread to the
wait queue, so that another thread can update the protected data whilst the first thread waits.
Secondly, the condition variable wait is still inside a while loop — condition variables can be subject to
spurious wake-ups, so it is important to check the actual condition being waited for when the call to wait
returns.
Be careful when you notify
Thirdly, the call to notify_one comes after the data is pushed on the internal queue. This avoids the
waiting thread being notified if the call to the_queue.push throws an exception. As written, the call to
notify_one is still within the protected region, which is potentially sub-optimal: the waiting thread might wake up
immediately it is notified, and before the mutex is unlocked, in which case it will have to block when the mutex is reacquired on
the exit from wait. By rewriting the function so that the notification comes after the mutex is unlocked, the
waiting thread will be able to acquire the mutex without blocking:
template<typename Data>
class concurrent_queue
{
public:
void push(Data const& data)
{
boost::mutex::scoped_lock lock(the_mutex);
bool const was_empty=the_queue.empty();
the_queue.push(data);
lock.unlock(); // unlock the mutex
if(was_empty)
{
the_condition_variable.notify_one();
}
}
// rest as before
};
Reducing the locking overhead
Though the use of a condition variable has improved the pushing and waiting side of the interface, the interface for the consumer
thread still has to perform excessive locking: wait_for_data, front and pop all lock the
mutex, yet they will be called in quick succession by the consumer thread.
By changing the consumer interface to a single wait_and_pop function, the extra lock/unlock calls can be avoided:
template<typename Data>
class concurrent_queue
{
public:
void wait_and_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
the_condition_variable.wait(lock);
}
popped_value=the_queue.front();
the_queue.pop();
}
// rest as before
};
Using a reference parameter to receive the result is used to transfer ownership out of the queue in order to avoid the exception
safety issues of returning data by-value: if the copy constructor of a by-value return throws, then the data has been removed from
the queue, but is lost, whereas with this approach, the potentially problematic copy is performed prior to modifying the queue (see
Herb Sutter's Guru Of The Week #8 for a discussion of the issues). This does, of
course, require that an instance Data can be created by the calling code in order to receive the result, which is not
always the case. In those cases, it might be worth using something like boost::optional to avoid this requirement.
Handling multiple consumers
As well as removing the locking overhead, the combined wait_and_pop function has another benefit — it
automatically allows for multiple consumers. Whereas the fine-grained nature of the separate functions makes them subject to race
conditions without external locking (one reason why the authors of the SGI
STL advocate against making things like std::vector thread-safe — you need external locking to do many common
operations, which makes the internal locking just a waste of resources), the combined function safely handles concurrent calls.
If multiple threads are popping entries from a full queue, then they just get serialized inside wait_and_pop, and
everything works fine. If the queue is empty, then each thread in turn will block waiting on the condition variable. When a new
entry is added to the queue, one of the threads will wake and take the value, whilst the others keep blocking. If more than one
thread wakes (e.g. with a spurious wake-up), or a new thread calls wait_and_pop concurrently, the while
loop ensures that only one thread will do the pop, and
the others will wait.
Update: As commenter David notes below, using multiple consumers does have one problem: if there are several
threads waiting when data is added, only one is woken. Though this is exactly what you want if only one item is pushed onto the
queue, if multiple items are pushed then it would be desirable if more than one thread could wake. There are two solutions to this:
use notify_all() instead of notify_one() when waking threads, or to call notify_one()
whenever any data is added to the queue, even if the queue is not currently empty. If all threads are notified then the extra
threads will see it as a spurious wake and resume waiting if there isn't enough data for them. If we notify with every
push() then only the right number of threads are woken. This is my preferred option: condition variable notify calls
are pretty light-weight when there are no threads waiting. The revised code looks like this:
template<typename Data>
class concurrent_queue
{
public:
void push(Data const& data)
{
boost::mutex::scoped_lock lock(the_mutex);
the_queue.push(data);
lock.unlock();
the_condition_variable.notify_one();
}
// rest as before
};
There is one benefit that the separate functions give over the combined one — the ability to check for an empty queue, and
do something else if the queue is empty. empty itself still works in the presence of multiple consumers, but the value
that it returns is transitory — there is no guarantee that it will still apply by the time a thread calls
wait_and_pop, whether it was true or false. For this reason it is worth adding an additional
function: try_pop, which returns true if there was a value to retrieve (in which case it retrieves it), or
false to indicate that the queue was empty.
template<typename Data>
class concurrent_queue
{
public:
bool try_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
if(the_queue.empty())
{
return false;
}
popped_value=the_queue.front();
the_queue.pop();
return true;
}
// rest as before
};
By removing the separate front and pop functions, our simple naive implementation has now become a
usable multiple producer, multiple consumer concurrent queue.
The Final Code
Here is the final code for a simple thread-safe multiple producer, multiple consumer queue:
template<typename Data>
class concurrent_queue
{
private:
std::queue<Data> the_queue;
mutable boost::mutex the_mutex;
boost::condition_variable the_condition_variable;
public:
void push(Data const& data)
{
boost::mutex::scoped_lock lock(the_mutex);
the_queue.push(data);
lock.unlock();
the_condition_variable.notify_one();
}
bool empty() const
{
boost::mutex::scoped_lock lock(the_mutex);
return the_queue.empty();
}
bool try_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
if(the_queue.empty())
{
return false;
}
popped_value=the_queue.front();
the_queue.pop();
return true;
}
void wait_and_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
the_condition_variable.wait(lock);
}
popped_value=the_queue.front();
the_queue.pop();
}
};
Posted by Anthony Williams
[/ threading /] permanent link
Tags: threading, thread safe, queue, condition variable
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
C++0x Draft and Concurrency Papers in the August 2008 Mailing
Thursday, 28 August 2008
Yesterday, the August 2008 C++ Standards Committee Mailing was published. This features a new Working Draft for C++0x, as well as quite a few other papers.
Thread-local storage
This draft incorporates N2659:
Thread-Local Storage, which was voted in at the June committee
meeting. This introduces a new keyword: thread_local
which can be used to indicate that each thread will have its own copy
of an object which would otherwise have static storage duration.
thread_local int global;
thread_local std::string constructors_allowed;
void foo()
{
struct my_class{};
static thread_local my_class block_scope_static;
}
As the example above shows, objects with constructors and
destructors can be declared thread_local. The constructor
is called (or other initialization done) before the first use of such
an object by a given thread. If the object is used on a given thread
then it is destroyed (and its destructor run) at thread exit. This is
a change from most common pre-C++0x implementations, which exclude
objects with constructors and destructors.
Additional concurrency papers
This mailing contains several papers related to concurrency and multithreading in C++0x. Some are just rationale or comments, whilst others are proposals which may well therefore be voted into the working draft at the September meeting. The papers are listed in numerical order.
- N2731: Proposed Text for Bidirectional Fences
- This is a revised version of N2633:
Improved support for bidirectional fences,
which incorporates naming changes requested by the committee at the
June meeting, along with some modifications to the memory model. In
particular, read-modify-write operations (such as
exchangeorfetch_add) that use thememory_order_relaxedordering can now feature as part of a release sequence, thus increasing the possibilities for usingmemory_order_relaxedoperations in lock-free code. Also, the definition of how fences that usememory_order_seq_cstinteract with othermemory_order_seq_cstoperations has been clarified. - N2744: Comments on Asynchronous Future Value Proposal
- This paper is a critique of N2671:
An Asynchronous Future Value: Proposed Wording. In short, the
suggestions are:
- that
shared_future<T>::get()should return by value rather than by const reference; - that
promiseobjects are copyable; - and that the
promisefunctions for setting the value and exception be overloaded with versions that return an error code rather than throwing an exception on failure.
- that
- N2745: Example POWER Implementation for C/C++ Memory Model
- This paper discusses how the C++0x memory model and atomic operations can be implemented on systems based on the POWER architecture. As a consequence, this also shows how the different memory orderings can affect the actual generated code for atomic operations.
- N2746: Rationale for the C++ working paper definition of "memory location"
- This paper is exactly what it says: a rationale for the definition
of "memory location". Basically, it discusses the reasons why every
object (even those of type
char) is a separate memory location, even though this therefore requires that memory be byte-addressable, and restricts optimizations on some architectures. - N2748: Strong Compare and Exchange
- In the current working paper, the atomic
compare_exchangefunctions are allowed to fail "spuriously" even when the value of the object was equal to the comparand. This allows efficient implementation on a wider variety of platforms than otherwise, but also requires almost all uses ofcompare_exchangeto be put in a loop. This paper proposes that instead we provide two variants:compare_exchange_weakandcompare_exchange_strong. The weak variant would be the same as the current version, whereas the strong variant would not be allowed to fail spuriously. On architectures which provide the strong variant by default (such as x86) this would remove the need for a loop in some cases.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: c++0x, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Design and Content Copyright © 2005-2026 Just Software Solutions Ltd. All rights reserved. | Privacy Policy