Technical Writings
- C++ Concurrency Book
- Articles and Publications
- Conference Presentations
- Recent Blog Entries
- Multithreading Blog Entries
- C++ Blog Entries
Subscribe to Blog
Blog Archives
Why do we need atomic_shared_ptr?
Friday, 21 August 2015
One of the new class templates provided in the upcoming
Concurrency TS
is
atomic_shared_ptr,
along with its counterpart atomic_weak_ptr. As you might guess, these are the
std::shared_ptr and std::weak_ptr equivalents of std::atomic<T*>, but why
would one need them? Doesn't std::shared_ptr already have to synchronize the
reference count?
std::shared_ptr and multiple threads
std::shared_ptr works great in multiple threads, provided each thread has its
own copy or copies. In this case, the changes to the reference count are indeed
synchronized, and everything just works, provided of course that what you do
with the shared data is correctly synchronized.
class MyClass;
void thread_func(std::shared_ptr<MyClass> sp){
sp->do_stuff();
std::shared_ptr<MyClass> sp2=sp;
do_stuff_with(sp2);
}
int main(){
std::shared_ptr<MyClass> sp(new MyClass);
std::thread thread1(thread_func,sp);
std::thread thread2(thread_func,sp);
thread2.join();
thread1.join();
}In this example, you need to ensure that it is safe to call
MyClass::do_stuff() and do_stuff_with() from multiple threads concurrently
on the same instance, but the reference counts are handled OK.
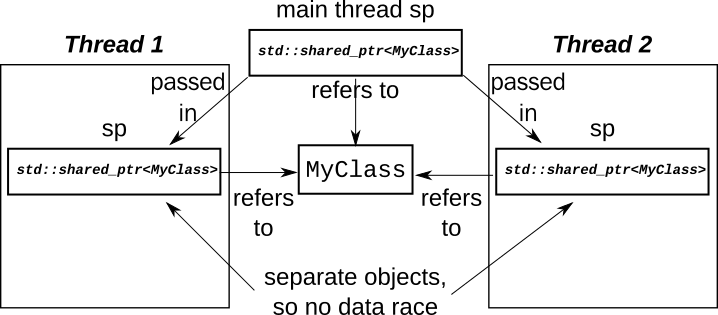
The problems come when you try and share a single std::shared_ptr instance
between threads.
Sharing a std::shared_ptr instance between threads
I could provide a trivial example of a std::shared_ptr instance shared between
threads, but instead we'll look at something a little more interesting, to give
a better feel for why you might need it.
Consider for a moment a simple singly-linked list, where each node holds a pointer to the next:
class MyList{
struct Node{
MyClass data;
std::unique_ptr<Node> next;
};
std::unique_ptr<Node> head;
// constructors etc. omitted.
};If we're going to access this from 2 threads, then we have a choice:
- We could wrap the whole object with a mutex, so only one thread is accessing the list at a time, or
- We could try and allow concurrent accesses.
For the sake of this article, we're going to assume we're allowing concurrent accesses.
Let's start simply: we want to traverse the list. Writing a traversal function is easy:
class MyList{
void traverse(std::function<void(MyClass)> f){
Node* p=head.get();
while(p){
f(p->data);
p=p->next;
}
};Assuming the list is immutable, this is fine, but immutable lists are no fun! We want to remove items from the front of our list. What changes do we need to make to support that?
Removing from the front of the list
If everything was single threaded, removing an element would be easy:
class MyList{
void pop_front(){
Node* p=head.get();
if(p){
head=std::move(p->next);
}
}
};If the list is not empty, the new head is the next pointer of the old head. However, we've got multiple threads accessing this list, so things aren't so straightforward.
Suppose we have a list of 3 elements.
A -> B -> C
If one thread is traversing the list, and another is removing the first element, there is a potential for a race.
- Thread X reads the
headpointer for the list and gets a pointer to A. - Thread Y removes A from the list and deletes it.
- Thread X tries to access the
datafor node A, but node A has been deleted, so we have a dangling pointer and undefined behaviour.
How can we fix it?
The first thing to change is to make all our std::unique_ptrs into
std::shared_ptrs, and have our traversal function take a std::shared_ptr
copy rather than using a raw pointer. That way, node A won't be deleted
immediately, since our traversing thread still holds a reference.
class MyList{
struct Node{
MyClass data;
std::shared_ptr<Node> next;
};
std::shared_ptr<Node> head;
void traverse(std::function<void(MyClass)> f){
std::shared_ptr<Node> p=head;
while(p){
f(p->data);
p=p->next;
}
}
void pop_front(){
std::shared_ptr<Node> p=head;
if(p){
head=std::move(p->next);
}
}
// constructors etc. omitted.
};Unfortunately that only fixes that race condition. There is a second race that is just as bad.
The second race condition
The second race condition is on head itself. In order to traverse the list,
thread X has to read head. In the mean time, thread Y is updating head. This
is the very definition of a data race, and is thus undefined behaviour.
We therefore need to do something to fix it.
We could use a mutex to protect head. This would be more fine-grained than a
whole-list mutex, since it would only be held for the brief time when the
pointer was being read or changed. However, we don't need to: we can use
std::experimental::atomic_shared_ptr instead.
The implementation is allowed to use a mutex internally with
atomic_shared_ptr, in which case we haven't gained anything with respect to
performance or concurrency, but we have gained by reducing the maintenance
load on our code. We don't have to have an explicit mutex data member, and we
don't have to remember to lock it and unlock it correctly around every access to
head. Instead, we can defer all that to the implementation with a single line
change:
class MyList{
std::experimental::atomic_shared_ptr<Node> head;
};Now, the read from head no longer races with a store to head: the
implementation of atomic_shared_ptr takes care of ensuring that the load gets
either the new value or the old one without problem, and ensuring that the
reference count is correctly updated.
Unfortunately, the code is still not bug free: what if 2 threads try and remove a node at the same time.
Race 3: double removal
As it stands, pop_front assumes it is the only modifying thread, which leaves
the door wide open for race conditions. If 2 threads call pop_front
concurrently, we can get the following scenario:
- Thread X loads
headand gets a pointer to node A. - Thread Y loads
headand gets a pointer to node A. - Thread X replaces
headwithA->next, which is node B. - Thread Y replaces
headwithA->next, which is node B.
So, two threads call pop_front, but only one node is removed. That's a bug.
The fix here is to use the ubiquitous compare_exchange_strong function, a staple
of any programmer who's ever written code that uses atomic variables.
class MyList{
void pop_front(){
std::shared_ptr<Node> p=head;
while(p &&
!head.compare_exchange_strong(p,p->next));
}
};If head has changed since we loaded it, then the call to
compare_exchange_strong will return false, and reload p for us. We then
loop again, checking that p is still non-null.
This will ensure that two calls to pop_front removes two nodes (if there are 2
nodes) without problems either with each other, or with a traversing thread.
Experienced lock-free programmers might well be thinking "what about the ABA problem?" right about now. Thankfully, we don't have to worry!
What no ABA problem?
That's right, pop_front does not suffer from the ABA problem. Even assuming
we've got a function that adds new values, we can never get a new value of
head the same as the old one. This is an additional benefit of using
std::shared_ptr: the old node is kept alive as long as one thread holds a
pointer. So, thread X reads head and gets a pointer to node A. This node is
now kept alive until thread X destroys or reassigns that pointer. That means
that no new node can be allocated with the same address, so if head is equal
to the value p then it really must be the same node, and not just some
imposter that happens to share the same address.
Lock-freedom
I mentioned earlier that implementations may use a mutex to provide the
synchronization in atomic_shared_ptr. They may also manage to make it
lock-free. This can be tested using the is_lock_free() member function common
to all the C++ atomic types.
The advantage of providing a lock-free atomic_shared_ptr should be obvious: by
avoiding the use of a mutex, there is greater scope for concurrency of the
atomic_shared_ptr operations. In particular, multiple concurrent reads can
proceed unhindered.
The downside will also be apparent to anyone with any experience with lock-free code: the code is more complex, and has more work to do, so may be slower in the uncontended cases. The other big downside of lock-free code (maintenance and correctness) is passed over to the implementor!
It is my belief that the scalability benefits outweight the complexity, which is
why Just::Thread v2.2 will ship with a lock-free
atomic_shared_ptr implementation.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: cplusplus, concurrency, multithreading
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Design and Content Copyright © 2005-2026 Just Software Solutions Ltd. All rights reserved. | Privacy Policy
8 Comments
> Just::Thread v2.2 will ship with a lock-free atomic_shared_ptr implementation.
Very interesting! Care to give a hint about how it will go about doing this?
Just::Thread uses a split reference count for atomic_shared_ptr --- the shared_ptr control block holds a count of "external counters" in addition to the normal reference count, and each atomic_shared_ptr instance that holds a reference has a local count of threads accessing it concurrently.
Thanks for a useful article. I found, however, the incorrect code at the last example I guess. Isn't that "while((p = head) &&" insted of "while(p &&" ?
Thanks.
Looks like you wan't to solve the problem of your own-designed single-linked-list that can be solved with a mutex + shared_ptr with an 'full-loaded serialized' shared_ptr, that may block more in parallel uses, or not?
To make your atomic shared_ptr copy and assignment 'atomic' you must serialize (lock by a mutex / spin / somewhat) in entire call... or I'm missing something?
Great Article Anthony, This looks very useful
Is there a push for this to be in future versions of C++? (C++17?)
Cheers Kjell
Is a lock-free implementation truly possible? This almost sounds too good to be true: the staple MPMC lockfree queue structure by Michael-Scott and Fober-Orlarey-Letz both avoid talking about memory reclamation, which they cannot solve as part of the algorithm. The standard answers are to use garbage collection or maintain a lock-free free list, or something to this effect. If you had a lock-free shared pointer, you could implement this MPMC queue with perfectly deterministic reclamation and with any underlying general-purpose allocator. The existence of such a solution would seem like a pretty major breakthrough.
@Louis: Yes, a lock-free implementation is now possible, and shipping with Just::Thread v2.2. However, it requires a double-word compare and swap operation. Much of the literature on lock-free data structures assumes that you don't have such an operation available. If you do have a DWCAS, many lock-free data structures can be simplified.
From what I've seen the experimental::atomic header is not found anywhere. At least it's not included with clang Apple LLVM version 10.0.0 (Xcode 10.1). Maybe Apple left this out to avoid any chance of it being used in production and causing serious bugs. It would be a nice feature to have because the ability to keep a reference count on atomic pointers would open up a whole range of possibilities for new lock-free data structures. Right now Java has the edge because all objects are reference counted by default (for garbage collection purposes) and Java actually implemented atomics years before c or c++ did. If feels as if c/c++ are years behind in this area. Apparently it will be include in c++20 but this will take years before it becomes implemented in mainstream compilers.