Technical Writings
- C++ Concurrency Book
- Articles and Publications
- Conference Presentations
- Recent Blog Entries
- Multithreading Blog Entries
- C++ Blog Entries
Subscribe to Blog
Blog Archives
Blog Archive
std::shared_ptr's secret constructor
Friday, 24 July 2015
std::shared_ptr has a secret: a constructor that most users don't even know
exists, but which is surprisingly useful. It was added during the lead-up to the
C++11 standard, so wasn't in the TR1 version of shared_ptr, but it's been
shipped with gcc since at least gcc 4.3, and with Visual Studio since Visual
Studio 2010, and it's been in Boost since at least v1.35.0.
This constructor doesn't appear in most tutorials on std::shared_ptr. Nicolai
Josuttis devotes half a page to this constructor in the second edition of The
C++ Standard Library, but Scott Meyers doesn't even mention it in his item on
std::shared_ptr in Effective Modern C++.
So: what is this constructor? It's the aliasing constructor.
Aliasing shared_ptrs
What does this secret constructor do for us? It allows us to construct a new
shared_ptr instance that shares ownership with another shared_ptr, but which
has a different pointer value. I'm not talking about a pointer value that's just
been cast from one type to another, I'm talking about a completely different
value. You can have a shared_ptr<std::string> and a shared_ptr<double> share
ownership, for example.
Of course, only one pointer is ever owned by a given set of shared_ptr
objects, and only that pointer will be deleted when the objects are
destroyed. Just because you can create a new shared_ptr that holds a different
value, you don't suddenly get the second pointer magically freed as well. Only
the original pointer value used to create the first shared_ptr will be
deleted.
If your new pointer values don't get freed, what use is this constructor? It
allows you to pass out shared_ptr objects that refer to subobjects and keep
the parent alive.
Sharing subobjects
Suppose you have a class X with a member that is an instance of some class Y:
struct X{
Y y;
};Now, suppose you have a dynamically allocated instance of X that you're
managing with a shared_ptr<X>, and you want to pass the Y member to a
library that takes a shared_ptr<Y>. You could construct a shared_ptr<Y> that
refers to the member, with a do-nothing deleter, so the library doesn't actually
try and delete the Y object, but what if the library keeps hold of the
shared_ptr<Y> and our original shared_ptr<X> goes out of scope?
struct do_nothing_deleter{
template<typename> void operator()(T*){}
};
void store_for_later(std::shared_ptr<Y>);
void foo(){
std::shared_ptr<X> px(std::make_shared<X>());
std::shared_ptr<Y> py(&px->y,do_nothing_deleter());
store_for_later(py);
} // our X object is destroyedOur stored shared_ptr<Y> now points midway through a destroyed object, which
is rather undesirable. This is where the aliasing constructor comes in: rather
than fiddling with deleters, we just say that our shared_ptr<Y> shares
ownership with our shared_ptr<X>. Now our shared_ptr<Y> keeps our X object
alive, so the pointer it holds is still valid.
void bar(){
std::shared_ptr<X> px(std::make_shared<X>());
std::shared_ptr<Y> py(px,&px->y);
store_for_later(py);
} // our X object is kept aliveThe pointer doesn't have to be directly related at all: the only requirement is
that the lifetime of the new pointer is at least as long as the lifetime of the
shared_ptr objects that reference it. If we had a new class X2 that held a
dynamically allocated Y object we could still use the aliasing constructor to
get a shared_ptr<Y> that referred to our dynamically-allocated Y object.
struct X2{
std::unique_ptr<Y> y;
X2():y(new Y){}
};
void baz(){
std::shared_ptr<X2> px(std::make_shared<X2>());
std::shared_ptr<Y> py(px,px->y.get());
store_for_later(py);
} // our X2 object is kept aliveThis could be used for classes that use the pimpl idiom, or trees where you
want to be able to pass round pointers to the child nodes, but keep the whole
tree alive. Or, you could use it to keep a shared library alive as long as a
pointer to a variable stored in that library was being used. If our class X
loads the shared library in its constructor and unloads it in the destructor,
then we can pass round shared_ptr<Y> objects that share ownership with our
shared_ptr<X> object to keep the shared library from being unloaded until all
the shared_ptr<Y> objects have been destroyed or reset.
The details
The constructor signature looks like this:
template<typename Other,typename Target>
shared_ptr(shared_ptr<Other> const& other,Target* p);As ever, if you're constructing a shared_ptr<T> then the pointer p must be
convertible to a T*, but there's no restriction on the type of Other at
all. The newly constructed object shares ownership with other, so
other.use_count() is increased by 1, and the value returned by get() on the
new object is static_cast<T*>(p).
There's a slight nuance here: if other is an empty shared_ptr, such as a
default-constructed shared_ptr, then the new shared_ptr is also empty, and
has a use_count() of 0, but it has a non-NULL value if p was not
NULL.
int i;
shared_ptr<int> sp(shared_ptr<X>(),&i);
assert(sp.use_count()==0);
assert(sp.get()==&i);Whether this odd effect has any use is open to debate.
Final Thoughts
This little-known constructor is potentially very useful for passing around
shared_ptr objects that reference parts of a non-trivial data structure and
keep the whole data structure alive. Not everyone will need it, but for those
that do it will avoid a lot of headaches.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: shared_ptr, cplusplus
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
All the world's a stage... C++ Actors from Just::Thread Pro
Wednesday, 15 July 2015
Handling shared mutable state is probably the single hardest part of writing multithreaded code. There are lots of ways to address this problem; one of the common ones is the actors metaphor. Going back to Hoare's Communicating Sequential Processes, the idea is simple - you build your program out of a set of actors that send each other messages. Each actor runs normal sequential code, occasionally pausing to receive incoming messages from other actors. This means that you can analyse the behaviour of each actor independently; you only need to consider which messages might be received at each receive point. You could treat each actor as a state machine, with the messages triggering state transitions.
This is how Erlang processes work: each process is an actor, which runs independently from the other processes, except that they can send messages to each other. Just::thread Pro: Actors Edition adds library facilities to support this to C++. In the rest of this article I will describe how to write programs that take advantage of it. Though the details will differ, the approach can be used with other libraries that provide similar facilities, or with the actor support in other languages.
Simple Actors
Actors are embodied in the
jss::actor
class. You pass in a function or other callable object (such as a lambda
function) to the constructor, and this function is then run on a background
thread. This is exactly the same as for
std::thread,
except that the destructor waits for the actor thread to finish, rather than
calling std::terminate.
void simple_function(){
std::cout<<"simple actor\n";
}
int main(){
jss::actor actor1(simple_function);
jss::actor actor2([]{
std::cout<<"lambda actor\n";
});
}The waiting destructor is nice, but it's really a side issue — the main benefit of actors is the ability to communicate using messages rather than shared state.
Sending and receiving messages
To send a message to an actor you just call the
send()
member function on the actor object, passing in whatever message you wish to
send. send() is a function template, so you can send any type of message
— there are no special requirements on the message type, just that it is a
MoveConstructible type. You can also use the stream-insertion operator to send
a message, which allows easy chaining e.g.
actor1.send(42);
actor2.send(MyMessage("some data"));
actor2<<Message1()<<Message2();Sending a message to an actor just adds it to the actor's message queue. If the
actor never checks the message queue then the message does nothing. To check the
message queue, the actor function needs to call the
receive()
static member function of
jss::actor. This
is a static member function so that it always has access to the running actor,
anywhere in the code — if it were a non-static member function then you
would need to ensure that the appropriate object was passed around, which would
complicate interfaces, and open up the possibility of the wrong object being
passed around, and lifetime management issues.
The call to jss::actor::receive() will then block the actor's thread until a
message that it can handle has been received. By default, the only message type
that can be handled is jss::stop_actor. If a message of this type is sent to
an actor then the receive() function will throw a jss::stop_actor
exception. Uncaught, this exception will stop the actor running. In the
following example, the only output will be "Actor running", since the actor will
block at the receive() call until the stop message is sent, and when the message
arrives, receive() will throw.
void stoppable_actor(){
std::cout<<"Actor running"<<std::endl;
jss::actor::receive();
std::cout<<"This line is never run"<<std::endl;
}
int main(){
jss::actor a1(stoppable_actor);
std::this_thread::sleep_for(std::chrono::seconds(1));
a1.send(jss::stop_actor());
}Sending a "stop" message is common-enough that there's a special member function
for that too:
stop(). "a1.stop()"
is thus equivalent to "a1.send(jss::stop_actor())".
Handling a message of another type requires that you tell the receive() call
what types of message you can handle, which is done by chaining one or more
calls to the
match()
function template. You must specify the type of the message to handle, and then
provide a function to call if the message is received. Any messages other than
jss::stop_actor not specified in a match() call will be removed from the queue,
but otherwise ignored. In the following example, only messages of type "int" and
"std::string" are accepted; the output is thus:
Waiting
42
Waiting
Hello
Waiting
DoneHere's the code:
void simple_receiver(){
while(true){
std::cout<<"Waiting"<<std::endl;
jss::actor::receive()
.match<int>([](int i){std::cout<<i<<std::endl;})
.match<std::string>([](std::string const&s){std::cout<<s<<std::endl;});
}
}
int main(){
{
jss::actor a(simple_receiver);
a.send(true);
a.send(42);
a.send(std::string("Hello"));
a.send(3.141);
a.send(jss::stop_actor());
} // wait for actor to finish
std::cout<<"Done"<<std::endl;
}It is important to note that the receive() call will block until it receives
one of the messages you have told it to handle, or a jss::stop_actor message,
and unexpected messages will be removed from the queue and discarded. This means
the actors don't accumulate a backlog of messages they haven't yet said they can
handle, and you don't have to worry about out-of-order messages messing up a
receive() call.
These simple examples have just had main() sending messages to the actors. For
a true actor-based system we need them to be able to send messages to each
other, and reply to messages. Let's take a look at how we can do that.
Referencing one actor from another
Suppose we want to write a simple time service actor, that sends the current
time back to any other actor that asks it for the time. At first thought it
looks rather simple: write a simple loop that handles a "time request" message,
gets the time, and sends a response. It won't be that much different from our
simple_receiver() function above:
struct time_request{};
void time_server(){
while(true){
jss::actor::receive()
.match<time_request>([](time_request r){
auto now=std::chrono::system_clock::now();
????.send(now);
});
}
}The problem is, we don't know which actor to send the response to — the
whole point of this time server is that it will respond to a message from any
other actor. The solution is to pass the sender as part of the message. We could
just pass a pointer or reference to the jss::actor instance, but that requires
that the actor knows the location of its own controlling object, which makes it
more complicated — none of the examples we've had so far could know that,
since the controlling object is a local variable declared in a separate
function. What is needed instead is a simple means of identifying an actor,
which the actor code can query — an actor reference. The type of an actor
reference is
jss::actor_ref,
which is implicitly constructible from a jss::actor. An actor can also obtain
a reference to itself by calling
jss::actor::self(). jss::actor_ref
has a
send()
member function and stream insertion operator for sending messages, just like
jss::actor. So, we can put the sender of our time_request message in the message
itself as a jss::actor_ref data member, and use that when sending the response.
struct time_request{
jss::actor_ref sender;
};
void time_server(){
while(true){
jss::actor::receive()
.match<time_request>([](time_request r){
auto now=std::chrono::system_clock::now();
r.sender<<now;
});
}
}
void query(jss::actor_ref server){
server<<time_request{jss::actor::self()};
jss::actor::receive()
.match<std::chrono::system_clock::time_point>(
[](std::chrono::system_clock::time_point){
std::cout<<"time received"<<std::endl;
});
}Dangling references
If you use jss::actor_ref then you have to be prepared for the case that the
referenced actor might have stopped executing by the time you send the
message. In this case, any attempts to send a message through the
jss::actor_ref instance will throw an exception of type
[jss::no_actor]http://www.stdthread.co.uk/prodoc/headers/actor/no_actor.html. To
be robust, our time server really ought to handle that too — if an
unhandled exception of any type other than jss::stop_actor escapes the actor
function then the library will call std::terminate. We should therefore wrap the
attempt to send the message in a try-catch block.
void time_server(){
while(true){
jss::actor::receive()
.match<time_request>([](time_request r){
auto now=std::chrono::system_clock::now();
try{
r.sender<<now;
} catch(jss::no_actor&){}
});
}
}We can now set up a pair of actors that play ping-pong:
struct pingpong{
jss::actor_ref sender;
};
void pingpong_player(std::string message){
while(true){
try{
jss::actor::receive()
.match<pingpong>([&](pingpong msg){
std::cout<<message<<std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(50));
msg.sender<<pingpong{jss::actor::self()};
});
}
catch(jss::no_actor&){
std::cout<<"Partner quit"<<std::endl;
break;
}
}
}
int main(){
jss::actor ping(pingpong_player,"ping");
jss::actor pong(pingpong_player,"pong");
ping<<pingpong{pong};
std::this_thread::sleep_for(std::chrono::seconds(1));
ping.stop();
pong.stop();
}This will give output along the lines of the following:
ping
pong
ping
pong
ping
pong
ping
pong
ping
pong
ping
pong
ping
pong
ping
pong
ping
pong
ping
pong
Partner quitThe sleep in the player's message handler is to slow everything down — if
you take it out then messages will go back and forth as fast as the system can
handle, and you'll get thousands of lines of output. However, even at full speed
the pings and pongs will be interleaved, because sending a message synchronizes
with the receive() call that receives it.
That's essentially all there is to it — the rest is just application design. As an example of how it can all be put together, let's look at an implementation of the classic sleeping barber problem.
The Lazy Barber
For those that haven't met it before, the problem goes like this: Mr Todd runs a barber shop, but he's very lazy. If there are no customers in the shop then he likes to go to sleep. When a customer comes in they have to wake him up if he's asleep, take a seat if there is one, or come back later if there are no free seats. When Mr Todd has cut someone's hair, he must move on to the next customer if there is one, otherwise he can go back to sleep.
The barber actor
Let's start with the barber. He sleeps in his chair until a customer comes in, then wakes up and cuts the customer's hair. When he's done, if there is a waiting customer he cuts that customer's hair. If there are no customers, he goes back to sleep, and finally at closing time he goes home. This is shown as a state machine in figure 1.
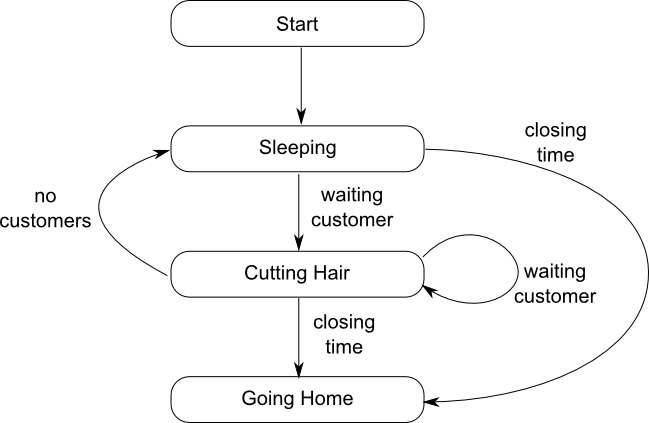
This translates into code as shown in listing 1.The wait
loops for "sleeping" and "cutting hair" have been combined, since almost the
same set of messages is being handled in each case — the only difference
is that the "cutting hair" state also has the option of "no customers", which
cannot be received in the "sleeping" state, and would be a no-op if it was. This
allows the action associated with the "cutting hair" state to be entirely
handled in the lambda associated with the customer_waiting message; splitting
the wait loops would require that the code was extracted out to a separate
function, which would make it harder to keep count of the haircuts. Of course,
if you don't have a compiler with lambda support then you'll need to do that
anyway. The logger is a global actor that receives std::strings as messages
and writes them to std::cout. This avoids any synchronization issues with
multiple threads trying to write out at once, but it does mean that you have to
pre-format the strings, such as when logging the number of haircuts done in the
day. The code for this is shown in listing 2.
The customer actor
Let's look at things from the other side: the customer. The customer goes to town, and does some shopping. Each customer periodically goes into the barber shop to try and get a hair cut. If they manage, or the shop is closed, then they go home, otherwise they do some more shopping and go back to the barber shop later. This is shown in the state machine in figure 2.
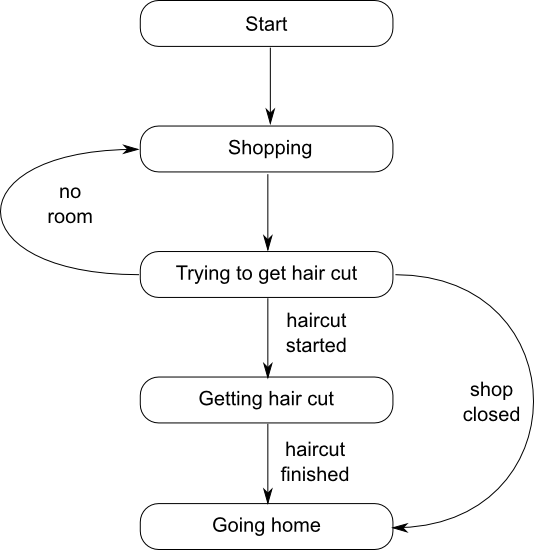
This translates into the code in listing 3. Note that the customer
interacts with a "shop" actor that I haven't mentioned yet. It is often
convenient to have an actor that represents shared state, since this allows
access to the shared state from other actors to be serialized without needing an
explicit mutex. In this case, the shop holds the number of waiting customers,
which must be shared with any customers that come in, so they know whether there
is a free chair or not. Rather than have the barber have to deal with messages
from new customers while he is cutting hair, the shop acts as an
intermediary. The customer also has to handle the case that the shop has already
closed, so the shop reference might refer to an actor that has finished
executing, and thus get a jss::no_actor exception when trying to send
messages.
The message handlers for the shop are short, and just send out further messages to the barber or the customer, which is ideal for a simple state-manager — you don't want other actors waiting to perform simple state checks because the state manager is performing a lengthy operation; this is why we separated the shop from the barber. The shop has 2 states: open, where new customers are accepted provided there are fewer than the remaining spaces, and closed, where new customers are turned away, and the shop is just waiting for the last customer to leave. If a customer comes in, and there is a free chair then a message is sent to the barber that there is a customer waiting; if there is no space then a message is sent back to the customer to say so. When it's closing time then we switch to the "closing" state — in the code we exit the first while loop and enter the second. This is all shown in listing 4.
The messages are shown in listing 5, and the main() function that drives it all is in listing 6.
Exit stage left
There are of course other ways of writing code to deal with any particular scenario, even if you stick to using actors. This article has shown some of the issues that you need to think about when using an actor-based approach, as well as demonstrating how it all fits together with the Just::Thread Pro actors library. Though the details will be different, the larger issues will be common to any implementation of the actor model.
Get the code
If you want to download the code for a better look, or to try it out, you can download it here.
Get your copy of Just:::Thread Pro
If you like the idea of working with actors in your code, now is the ideal time to get Just::Thread Pro. Get your copy now.
This blog post is based on an article that was printed in the July 2013 issue of CVu, the Journal of the ACCU.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: cplusplus, actors, concurrency, multithreading
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
New Concurrency Features in C++14
Wednesday, 08 July 2015
It might have been out for 7 months already, but the C++14 standard is still pretty fresh. The changes include a couple of enhancements to the thread library, so I thought it was about time I wrote about them here.
Shared locking
The biggest of the changes is the addition of
std::shared_timed_mutex. This
is a multiple-reader, single-writer mutex. This means that in addition to the
single-ownership mode supported by the other standard mutexes, you can also lock
it in shared ownership mode, in which case multiple threads may hold a shared
ownership lock at the same time.
This is commonly used for data structures that are read frequently but modified only rarely. When the data structure is stable, all threads that want to read the data structure are free to do so concurrently, but when the data structure is being modified then only the thread doing the modification is permitted to access the data structure.
The timed part of the name is analagous to
std::timed_mutex
and
std::recursive_timed_mutex:
timeouts can be specified for any attempt to acquire a lock, whether a
shared-ownership lock or a single-ownership lock. There is a proposal to add a
plain std::shared_mutex to the next standard, since this can have lower
overhead on some platforms.
To manage the new shared ownership mode there are a new set of member functions:
lock_shared(),
try_lock_shared(),
unlock_shared(),
try_lock_shared_for()
and
try_lock_shared_until(). Obtaining
and releasing the single-ownership lock is performed with the same set of
operations as for std::timed_mutex.
However, it is generally considered bad practise to use these functions directly
in C++, since that leaves the possibility of dangling locks if a code path
doesn't release the lock correctly. It is better to use
std::lock_guard
and
std::unique_lock
to perform lock management in the single-ownership case, and the
shared-ownership case is no different: the C++14 standard also provides a new
std::shared_lock
class template for managing shared ownership locks. It works just the same as
std::unique_lock; for common use cases it acquires the lock in the
constructor, and releases it in the destructor, but there are member functions
to allow alternative access patterns.
Typical uses will thus look like the following:
std::shared_timed_mutex m;
my_data_structure data;
void reader(){
std::shared_lock<std::shared_timed_mutex> lk(m);
do_something_with(data);
}
void writer(){
std::lock_guard<std::shared_timed_mutex> lk(m);
update(data);
}Performance warning
The implementation of a mutex that supports shared ownership is inherently more
complex than a mutex that only supports exclusive ownership, and all the
shared-ownership locks still need to modify the mutex internals. This means that
the mutex itself can become a point of contention, and sap performance. Whether
using a std::shared_timed_mutex instead of a std::mutex provides better or
worse performance overall is therefore strongly dependent on the work load and
access patterns.
As ever, I therefore strongly recommend profiling your application with
std::mutex and std::shared_timed_mutex in order to ascertain which performs
best for your use case.
std::chrono enhancements
The other concurrency enhancements in the C++14 standard are all in the
<chrono> header. Though this isn't strictly about concurrency, it is used for
all the timing-related functions in the concurrency library, and is therefore
important for any threaded code that has timeouts.
constexpr all round
The first change is that the library has been given a hefty dose of constexpr
goodness. Instances of std::chrono::duration and std::chrono::time_point now
have constexpr constructors and simple arithmetic operations are also
constexpr. This means you can now create durations and time points which are
compile-time constants. It also means they are literal types, which is
important for the other enhancement to <chrono>: user-defined literals for
durations.
User-defined literals
C++11 introduced the idea of user-defined literals, so you could provide a
suffix to numeric and string literals in your code to construct a user-defined
type of object, much as 3.2f creates a float rather than the default
double, however there were no new types of literals provided by the standard
library.
C++14 changes that. We now have user-defined literals for
std::chrono::duration, so you can write 30s instead of
std::chrono::seconds(30). To get this user-defined literal goodness you need
to explicitly enable it in your code with a using directive — you might have
other code that wants to use these suffixes for a different set of types, so the
standard let's you choose.
That using directive is:
using namespace std::literals::chrono_literals;The supported suffixes are:
h→std::chrono::hoursmin→std::chrono::minutess→std::chrono::secondsms→std::chrono::millisecondsus→std::chrono::microsecondsns→std::chrono::nanoseconds
You can therefore wait for a shared ownership lock with a 50 millisecond timeout like this:
void foo(){
using namespace std::literals::chrono_literals;
std::shared_lock<std::shared_timed_mutex> lk(m,50ms);
if(lk.owns_lock()){
do_something_with_lock_held();
}
else {
do_something_without_lock_held();
}
}Just::Thread support
As you might expect, Just::Thread provides an
implementation of all of this. std::shared_timed_mutex is available on all
supported platforms, but the constexpr and user-defined literal enhancements
are only available for those compilers that support the new language features:
gcc 4.6 or later for constexpr and gcc 4.7 or later for user-defined
literals, with the -std=c++11 or std=c++14 switch enabled in either case.
Get your copy of Just::Thread while
our 10th anniversary sale is on for a 50% discount.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: cplusplus, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
10th Anniversary Sale
Wednesday, 01 July 2015
We started Just Software Solutions Ltd in June 2005, so we've now been in business for 10 years. We're continuing to thrive, with both our consulting, training and development services, and sales of Just::Thread doing well.
To let our customers join in with our celebrations, we're running a month long sale: for the whole of July 2015, Just::Thread and Just::Thread Pro will be available for 50% off the normal price.
Just::Thread is our implementation of the C++11 and C++14 thread libraries, for Windows, Linux and MacOSX. It also includes some of the extensions from the upcoming C++ Concurrency TS, with more to come shortly.
Just::Thread Pro is our add-on library which provides an Actor framework for easier concurrency, along with concurrent data structures: a thread-safe queue, and concurrent hash map, and a wrapper for ensuring synchronized access to single objects.
All licences include a free upgrade to point releases, so if you purchase now you'll get a free upgrade to all 2.x releases.
Posted by Anthony Williams
[/ news /] permanent link
Tags: sale
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Standardizing Variant: Difficult Decisions
Wednesday, 17 June 2015
One of the papers proposed for the next version of the C++ Standard is N4542: Variant: a type safe union (v4). As you might guess from the (v4) in the title, this paper has been discussed several times by the committee, and revised in the light of discussions.
Boost has had a variant type for a long time, so it only
seems natural to standardize it. However, there are a couple of design decisions
made for boost::variant which members of the committee were uncomfortable
with, so the current paper has a couple of differences from
boost::variant. The most notable of these is that boost::variant has a
"never empty" guarantee, whereas N4542 proposes a variant that can be empty.
Why do we need empty variants?
Let's assume for a second that our variant is never empty, as per
boost::variant, and consider the following code with two classes A and B:
variant<A,B> v1{A()};
variant<A,B> v2{B()};
v1=v2;Before the assignment, v1 holds a value of type A. After the assignment
v1=v2, v1 has to hold a value of type B, which is a copy of the value held
in v2. The assignment therefore has to destroy the old value of type A and
copy-construct a new value of type B into the internal storage of v1.
If the copy-construction of B does not throw, then all is well. However, if
the copy construction of B does throw then we have a problem: we just
destroyed our old value (of type A), so we're in a bit of a predicament
— the variant isn't allowed to be empty, but we don't have a value!
Can we fix it? Double buffering
In 2003 I wrote
an article about this,
proposing a solution involving double-buffering: the variant type could contain
a buffer big enough to hold both A and B. Then, the assignment operator
could copy-construct the new value into the empty space, and only destroy the
old value if this succeeded. If an exception was thrown then the old value is
still there, so we avoid the previous predicament.
This technique isn't without downsides though. Firstly, this can double the size of the variant, as we need enough storage for the two largest types in the variant. Secondly, it changes the order of operations: the old value is not destroyed until after the new one has been constructed, which can have surprising consequences if you are not expecting it.
The current implementation of boost::variant avoids the first problem by
constructing the secondary buffer on the fly. This means that assignment of
variants now involves dynamic memory allocation, but does avoid the double-space
requirement. However, there is no solution for the second problem: avoiding
destroying the old value until after the new one has been constructed cannot be
avoided while maintaining the never-empty guarantee in the face of throwing copy
constructors.
Can we fix it? Require no-throw copy construction
Given that the problem only arises due to throwing copy constructors, we could easily avoid the problem by requiring that all types in the variant have a no-throw copy constructor. The assignment is then perfectly safe, as we can destroy the old value, and copy-construct the new one, without fear of an exception throwing a spanner in the works.
Unfortunately, this has a big downside: lots of useful types that people want to
put in variants like std::string, or std::vector, have throwing copy
constructors, since they must allocate memory, and people would now be unable to
store them directly. Instead, people would have to use
std::shared_ptr<std::string> or create a wrapper that stored the exception in
the case that the copy constructor threw an exception.
template<typename T>
class value_or_exception{
private:
std::optional<T> value;
std::exception_ptr exception;
public:
value_or_exception(T const& v){
try{
value=v;
} catch(...) {
exception=std::current_exception();
}
}
value_or_exception(value_or_exception const& v){
try{
value=v.value;
exception=v.exception;
} catch(...) {
exception=std::current_exception();
}
return *this;
}
value_or_exception& operator=(T const& v){
try{
value=v;
exception=std::exception_ptr();
} catch(...) {
exception=std::current_exception();
}
return *this;
}
// more constructors and assignment operators
T& get(){
if(exception){
std::rethrow_exception(exception);
}
return *value;
}
};Given such a template you could have
variant<int,value_or_exception<std::string>>, since the copy constructor would
not throw. However, this would make using the std::string value that little
bit harder due to the wrapper — access to it would require calling get()
on the value, in addition to the code required to retrieve it from the variant.
variant<int,value_or_exception<std::string>> v=get_variant_from_somewhere();
std::string& s=std::get<value_or_exception<std::string>>(v).get();The code that retrieves the value then also needs to handle the case that the
variant might be holding an exception, so get() might throw.
Can we fix it? Tag types
One proposed solution is to add a special case if one of the variant types is a
special tag type like
empty_variant_t. e.g. variant<int,std::string,empty_variant_t. In this case,
if the copy constructor throws then the special empty_variant_t type is stored
in the variant instead of what used to be there, or what we tried to
assign. This allows people who are OK with the variant being empty to use this
special tag type as a marker — the variant is never strictly "empty", it
just holds an instance of the special type in the case of an exception, which
avoids the problems with out-of-order construction and additional
storage. However, it leaves the problems for those that don't want to use the
special tag type, and feels like a bit of a kludge.
Do we need to fix it?
Given the downsides, we have to ask: is any of this really any better than allowing an empty state?
If we allow our variant to be empty then the code is simpler: we just write
for the happy path in the main code. If the assignment throws then we will get
an exception at that point, which we can handle, and potentially store a new
value in the variant there. Also, when we try and retrieve the value then we
might get an exception there if the variant is empty. However, if the expected
scenario is that the exception will never actually get thrown, and if it does
then we have a catastrophic failure anyway, then this can greatly simplify the
code.
For example, in the case of variant<int,std::string>, the only reason
you'd get an exception from the std::string copy constructor was due to
insufficient memory. In many applications, running out of dynamic memory is
exceedingly unlikely (the OS will just allocate swap space), and indicates an
unrecoverable scenario, so we can get away with assuming it won't happen. If our
application isn't one of these, we probably know it, and will already be writing
code to carefully handle out-of-memory conditions.
Other exceptions might not be so easily ignorable, but in those cases you probably also have code designed to handle the scenario gracefully.
A variant with an "empty" state is a bit like a pointer in the sense that you
have to check for NULL before you use it, whereas a variant without an empty
state is more like a reference in that you can rely on it having a value. I can
see that any code that handles variants will therefore get filled with asserts
and preconditions to check the non-emptiness of the variant.
Given the existence of an empty variant, I would rather that the various
accessors such as get<T>() and get<Index>() threw an exception on the empty
state, rather than just being ill-formed.
Default Construction
Another potentially contentious area is that of default construction: should a
variant type be default constructible? The current proposal has variant<A,B>
being default-constructible if and only if A (the first listed type) is
default-constructible, in which case the default constructor default-constructs an
instance of A in the variant. This mimics the behaviour of the core language
facility union.
This means that variant<A,B> and variant<B,A> behave differently with
respect to default construction. For starters, the default-constructed type is
different, but also one may be default-constructible while the other is not. For
some people this is a surprising result, and undesirable.
One alternative options is that default construction picks the first default-constructible type from the list, if there are any, but this still has the problem of different orderings behaving differently.
Given that variants can be empty, another alternative is to have the default constructed variant be empty. This avoids the problem of different orderings behaving differently, and will pick up many instances of people forgetting to initialize their variants, since they will now be empty rather than holding a default-constructed value.
My preference is for the third option: default constructed variants are empty.
Duplicate types
Should we allow variant<T,T>? The current proposal allows it, and makes the
values distinct. However, it comes with a price: you cannot simply construct a
variant<T,T> from a T: instead you must use the special constructors that
take an emplaced_index_t<I> as the first parameter, to indicate which entry
you wish to construct. Similarly, you can now no longer retrieve the value
merely by specifying the type to retrieve: you must specify the index, as this
is now significant.
I think this is unnecessary overhead for a seriously niche feature. If people
want to have two entries of the same type, but with different meanings, in their
variant then they should use the type system to make them different. It's
trivial to write a tagged_type template, so you can have tagged_type<T,struct SomeTag>and tagged_type<T,struct OtherTag> which are distinct types, and thus
easily discriminated in the variant. Many people would argue that even this is
not going far enough: you should embrace the Whole Value Idiom, and write a
proper class for each distinct meaning.
Given that, I think it thus makes sense for variant<T,T> to be ill-formed. I'm
tempted to make it valid, and the same as variant<T>, but too much of the
interface depends on the index of the type in the type list. If I have
variant<T,U,T,T,U,int>, what is the type index of the int, or the T for
that matter? I'd rather not have to answer such questions, so it seems better to
make it ill-formed.
What do you think?
What do you think about the proposed variant template? Do you agree with the design decisions? Do you have a strong opinion on the issues above, or some other aspect of the design?
Have your say in the comments below.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: cplusplus, standards, variant
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Slides and code and for my ACCU 2015 presentation
Wednesday, 17 June 2015
It's now two months since the ACCU 2015 conference in Bristol, UK, so I thought it was about time I posted my slides.
This year my presentation was titled "Safety: off - How not to shoot yourself in the foot with C++ atomics". I gave a brief introduction to the C++ atomics facilities, some worked examples of usage, and guidelines for how to use atomics safely in your code.
The slides are available here, and the code examples here.
Posted by Anthony Williams
[/ news /] permanent link
Tags: C++, lockfree, atomic, accu
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Cryptography and Society
Tuesday, 05 May 2015
Politicians in both the UK and USA have been making moves towards banning secure encryption over the last few months. With the UK general election coming on Thursday I wanted to express why I think this is a seriously bad idea.
Context
Back in January there were some terrorist attacks in Paris. These attacks were and are a serious matter, and stopping such attacks in future should be something that governments concern themselves with.
However, one aspect of the response by politicians has been to call for securely encrypted communication outlawed. In particular, the British Prime Minister, David Cameron, asked
"In our country, do we want to allow a means of communication between people which, even in extemis with a signed warrant from the Home Secretary personally, that we cannot read?"
It was clear from the context that he thinks the answer is a resounding "NO", and from the further actions of politicians both here and in the USA it appears that others in government agree with that point of view. They clearly believe that the government should be able to read all communications.
I think in a fair, open, democratic society, the answer must be "YES": private individuals must be able to communicate without risk of eavesdropping by government officials.
Secure Encryption is Not New
Firstly, there have ALWAYS been means of communication between people that the government cannot read. You might be able to intercept a letter, and read the words written on the piece of paper, but if the message is not in the words as they appear, then you cannot read it.
Ciphers which could not be cracked by contemporary eavesdroppers have been used since at least the time of the Roman Empire. New technology merely provides a new set of such ciphers.
For example, the proper use of a one-time pad provides completely secure encryption. This technique has been in use since 1882, if not earlier.
Other technology in widespread use today "merely" makes it exceedingly difficult to break the cipher, requiring hundreds, thousands or even millions of years to crack with a brute-force method. These time periods are enough that these ciphers can be considered uncrackable for all intents and purposes.
Consequently, governments are powerless to actually prevent communication that cannot be read by the security services. All that can be done is to make it hard for the average citizen to use such communication.
Terrorists are Criminals
By their very nature, terrorists are criminals: terrorist acts themselves are illegal, and even the possession of the weapons used for the terrorist acts is often also illegal.
Therefore, terrorists will not be put off from using secure communication just because that too is illegal.
In particular, criminal organisations will not think twice about using whatever means is available to ensure that their communications are private: if something gives them an edge of the police or anyone else who would seek to stop them, they will use it.
Society relies on secure encryption
Secure encrypted communication doesn't just prevent government agencies reading the communications of criminals, it also prevents criminals reading the communications of ordinary citizens.
This website, in common with an increasingly large number of websites, uses HTTPS for all traffic. When properly configured this means that someone intercepting the website traffic cannot identify which pages on the website you visited, or extract any of the data sent by you as a visitor to the website, or by the website back to you.
This is crucial for facilities such as online banking: it prevents computer criminals from obtaining passwords and account data by intercepting the communications between you and your bank. If such communications could not be relied upon to be secure then online banking would not be viable, as the potential for fraud due to stolen passwords would be too great.
Likewise, many businesses use secure Virtual Private Networks (VPNs) which rely on secure encryption to transfer data between computers that are only connected to each other via the internet. This allows them to securely transfer data between sites, or between remote workers, without worrying about the communications being intercepted by criminals. Without secure encryption, many large multi-national businesses would be hugely impacted, as they wouldn't be able to rely on transferring data across the internet safely, and would instead have to rely on physical transfer via courier.
A "back door" or "government secret key" destroys the security of encryption
Some of the proposals from politicians have been to require that companies that provide encryption services must also provide a means whereby government security services can also decrypt the communications if required.
This requires that either (a) the company in question keeps a database of all the encryption/decryption keys used for all communications, or (b) the encryption algorithm used allows for decryption via a "back door" or "secret key" in addition to the standard decryption key, so that the government security services can gain access if required, without needing to know the customer's decryption key.
Keeping a database of the decryption keys just provides a direct target for attack by computer criminals. Once such a database is breached, none of the communications provided by that company can be considered secure. This is clearly not a good state of affairs, given the number of times that password databases get compromised.
That leaves option (b): providing a "back door" or "secret key", or other means whereby an otherwise-encrypted communication can be read by the security services. However, this fundamentally compromises that encryption.
Knowing that the back door exists, criminal computer crackers will work to ensure that they too can gain access to the communication, and they won't wait for a warrant from the Home Secretary or whatever government department is responsible for issuing such warrants! Any such group that does manage to obtain access would probably not make it public knowledge, they would merely use it to ensure that they could access communications that were relevant to them, whether that was because they had a direct use for the information, or because it could be sold to other criminal organisations.
If there is a single key that can decrypt all communication using a given system then that dramatically reduces the computation effort required to break the key: the larger the number of messages that are transmitted with a given key, the easier it is to identify the key, especially if you have access to the raw unencrypted message. The huge volume of electronic communications in use today would mean that the secret back door key would be much more readily compromised than any individual encryption key.
Privacy is a human right
The Universal Declaration of Human Rights was adopted by the UN in 1948. Article 12 states:
No one shall be subjected to arbitrary interference with his privacy, family, home or correspondence, nor to attacks upon his honour and reputation. Everyone has the right to the protection of the law against such interference or attacks.
Secure encrypted communication protects our correspondence from interference, including interference by the government.
Restricting the use of encryption is also a violation of the right to freedom of expression, guaranteed to us by article 19 of the Universal Declaration of Human Rights:
Everyone has the right to freedom of opinion and expression; this right includes freedom to hold opinions without interference and to seek, receive and impart information and ideas through any media and regardless of frontiers.
The restriction on our freedom of expression is easy to see: if I have true freedom of expression then I can impart any series of letters or numbers to anyone without interference. If that series of letters or numbers happens to be an encrypted message then that is of no consequence. Any attempt to limit the use of particular encryption algorithms therefore limits my ability to send whatever message I like, since particular sequences of letters and numbers are outlawed purely because of their meaning.
Human rights organisations such as Amnesty International use secure encrypted communications to communicate with their workers. If those communications could not be secured against interference then this would have a detrimental impact on their ability to do their humanitarian work, and could endanger their workers.
Encryption is mathematics
Computer encryption is just a mathematical algorithm applied to a series of numbers. It is ridiculous to consider that performing mathematical operations on a sequence of numbers could be outlawed merely because that sequence of numbers has meaning to someone.
End note
I strongly object to any move to restrict the use of encryption technology. It is technologically and morally unsound, with little or no upside and considerable downsides.
I urge politicians to likewise oppose any moves to restrict the use of encryption technology, and I urge those standing in the elections in the UK this week to make it known to their potential constituents that they will oppose such measures.
Finally, I think we should be encouraging the use of strong encryption rather than discouraging it, to protect us from those who would intercept our digital communication and use that for their gain and our detriment.
Posted by Anthony Williams
[/ general /] permanent link
Tags: cryptography, encryption, politics
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Numbers in Javascript
Wednesday, 25 March 2015
I've been playing around with Javascript (strictly, ECMAScript) in my spare time recently, and one thing that I've noticed is that numbers are handled slightly strangely. I'm sure that many experienced Javascript programmers will just nod sagely and say "everyone knows that", but I've been using Javascript for a while and not encountered this strangeness before as I've not done extensive numerical processing, so I figured it was worth writing down.
Numbers are floating point
For the most part, Javascript numbers are floating point numbers. In particular,
they are standard IEEE 754 64-bit double-precision numbers. Even though the IEEE
spec allows for multiple NaN (Not-a-number) values, Javascript has exactly one
NaN value, which can be referenced in code as NaN.
This has immediate consequences: there are upper and lower limits to the stored value, and numbers can only have a certain precision.
For example, 10000000000000001 cannot be represented in Javascript. It is the same value as 10000000000000000.
var x=10000000000000000;
if(x==(x+1))
alert("Oops");This itself isn't particularly strange: one of the first things you learn about Javascript is that it has floating-point numbers. However, it's something that you need to bear in mind when trying to do any calculations involving very big numbers (larger than 9007199254740992 in magnitude) or where more than 53 bits of precision is needed (since IEEE 754 numbers have binary exponents and mantissas).
You might think that you don't need the precision, but you quickly hit problems when using decimal fractions:
var x=0.2*0.3-0.01;
if(x!=0.05)
alert("Oops");The rounding errors in the representations of the decimal fractions here mean
that the value of x in this example is 0.049999999999999996, not 0.05 as you
would hope.
Again, this isn't particularly strange, it's just an inherent property of the numbers being represented as floating point. However, what I found strange is that sometimes the numbers aren't treated as floating point.
Numbers aren't always floating point
Yes, that's right: Javascript numbers are sometimes not floating point numbers. Sometimes they are 32-bit signed integers, and very occasionally 32-bit unsigned integers.
The first place this happens is with the bitwise operators (&, |, ^): if
you use one of these then both operands are first converted to a 32-bit signed
integer. This can have surprising consequences.
Look at the following snippet of code:
var x=0x100000000; // 2^32
console.log(x);
console.log(x|0);What do you expect it to do? Surely x|0 is x? You might be excused for
thinking so, but no. Now, x is too large for a 32-bit integer, so x|0 forces
it to be taken modulo 2^32 before converting to a signed integer. The low
32-bits are all zero, so now x|0 is just 0.
OK, what about this case:
var x=0x80000000; // 2^31
console.log(x);
console.log(x|0);What do you expect now? We're under 2^32, so there's no dropping of higher order
bits, so surely x|0 is x now? Again, no. x|0 in this case is -x, because
x is first converted to a signed 32-bit integer with 2s complement
representation, which means the most-significant bit is the sign bit, so the
number is negative.
I have to confess, that even with the truncation to 32-bits, the use of signed integers for bitwise operations just seems odd. Doing bitwise operations on a signed number is a very unusual case, and is just asking for trouble, especially when the result is just a "number", so you can't rely on doing further operations and having them give you the result you would expect on a 32-bit integer value.
For example, you might want to mask off some bits from a value. With normal 2s
complement integers, x-(x&mask) is the same as x&~mask: in both cases,
you're left with the bits set in x that were not set in mask. With
Javascript, this doesn't work if x has bit 31 set.
var x=0xabcdef12;
var mask=0xff;
console.log(x-(x&mask));
console.log(x&~mask);If you truncate back to 32-bits with x|0 then the values are indeed the same,
but it's easy to forget.
Shifting bits
In languages such as C and C++, x<<y is exactly the same as x*(1<<y) if x
is an integer. Not so in Javascript. If you do a bitshift operation (<<, >>,
or >>>) then Javascript again converts your value to a signed integer before
and after the operation. This can have surprising results.
var x=0xaa;
console.log(x);
console.log(x<<24);
console.log(x*(1<<24));x<<24 converts x to a signed 32-bit integer, bit-shifts the value as a
signed 32-bit integer, and then converts that result back to a Number. In this
case, x<<24 has the bit pattern 0xaa000000, which has the highest bit set when
treated as 32-bit, so is now a negative number with value -1442840576. On the
other hand, 1<<24 does not have the high bit set, so is still positive, so
x*(1<<24) is a positive number, with the same value as 0xaa000000.
Of course, if the result of shifting would have more than 32 bits then the top
bits are lost: 0xaa<<25 would be truncated to 0x54000000, so has the value
1409286144, rather than the 5704253440 that you get from 0xaa*(1<<25).
Going right
For right-shifts, there are two operators: >> and >>>. Why two? Because the
operands are converted to signed numbers, and the two operators have different
semantics for negative operands.
What is 0x80000000 shifted right one bit? That depends. As an unsigned number,
right shift is just a divide-by-two operation, so the answer is 0x40000000, and
that's what you get with the >>> operator. The >>> operator shifts in
zeroes. On the other hand, if you think of this as a negative number (since it
has bit 31 set), then you might want the answer to stay negative. This is what
the >> operator does: it shifts in a 1 into the new bit 31, so negative
numbers remain negative.
As ever, this can have odd consequences if the initial number is larger than 32 bits.
var x=0x280000000;
console.log(x);
console.log(x>>1);
console.log(x>>>1);0x280000000 is a large positive number, but it's greater than 32-bits long, so
is first truncated to 32-bits, and converted to a signed
number. 0x280000000>>1 is thus not 0x140000000 as you might naively expect,
but -1073741824, since the high bits are dropped, giving 0x80000000, which is a
negative number, and >> preserves the sign bit, so we have 0xc0000000, which
is -1073741824.
Using >>> just does the truncation, so it essentially treats the operand as an
unsigned 32-bit number. 0x280000000>>>1 is thus 0x40000000.
If right shifts are so odd, why not just use division?
Divide and conquer?
If you need to preserve all the bits, then you might think that doing a division
instead of a shift is the answer: after all, right shifting is simply dividing
by 2^n. The problem here is that Javascript doesn't have integer division. 3/2
is 1.5, not 1. You're therefore looking at two floating-point operations instead
of one integer operation, as you have to discard the fractional part either by
removing the remainder beforehand, or by truncating it afterwards.
var x=3;
console.log(x);
console.log(x/2);
console.log((x-(x%2))/2);
console.log(Math.floor(x/2));Summary
For the most part, Javascript numbers are double-precision floating point, so need to be treated the same as you would floating point numbers in any other language.
However, Javascript also provides bitwise and shift operations, which first convert the operands to 32-bit signed 2s-complement values. This can have surprising consequences when either the input or result has a magnitude of more than 2^31.
This strikes me as a really strange choice for the language designers to make: doing bitwise operations on signed values is a really niche feature, whereas many people will want to do bitwise operations on unsigned values.
As browser Javascript processors get faster, and with the rise of things like Node.js for running Javascript outside a browser, Javascript is getting used for far more than just simple web-page effects. If you're planning on using it for anything involving numerical work or bitwise operations, then you need to be aware of this behaviour.
Posted by Anthony Williams
[/ javascript /] permanent link
Tags: javascript, numbers
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Firefox is losing market share to Chrome
Monday, 09 March 2015
I read with interest an article on Computerworld about Firefox losing market share, wondering what people were using instead. Unsurprisingly, the answer seems to be Chrome: apparently Chrome now has a 27.6% share compared to Firefox's 11.8%. That's quite a big difference.
I checkout out the stats for this site for February 2015, and the figures bear it out: 30.7% of visitors use Chrome vs 14.9% Firefox and 12.8% Safari. Amusingly, 3.1% of visitors still use IE6!
What I did find interesting is the version numbers people are using: there were visitors using every version of Chrome from version 2 to version 43, and the same for Firefox — someone was even using Firefox 0.10! I'm a bit surprised by this, as I'd have thought that users of these browsers were probably amongst the most likely to upgrade.
Why the drop?
The big question of course is why the shift? I switched to Firefox because Internet Explorer was poor, and I've stuck with it, mainly through inertia, but I've used other browsers over the years, and still prefer Firefox. I've got Chrome installed on my desktop, but I don't particularly like it, and only really use it for cross-browser testing. I only really use it on my tablets, where it is the only browser I have installed — I tried Firefox for Android and was really disappointed.
Maybe that's the cause of the shift: everyone is using mobile devices for browsing, and Chrome/Safari are better than the others for mobile.
Which browser(s) do you use, and why?
Posted by Anthony Williams
[/ general /] permanent link
Tags: firefox, chrome, browsers
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
just::thread C++11 and C++14 Thread Library V2.1 released
Tuesday, 03 March 2015
I am pleased to announce that version 2.1 of
just::thread, our C++11 and C++14 Thread Library
has just been released with support for new compilers.
This release adds the long-awaited support for gcc 4.8 on MacOSX, as well as bringing linux support right up to date with support for gcc 4.9 on Ubuntu and Fedora.
Just::Thread is now supported for the following compilers:
- Microsoft Windows XP and later:
- Microsoft Visual Studio 2005, 2008, 2010, 2012 and 2013
- TDM gcc 4.5.2, 4.6.1 and 4.8.1
- Debian and Ubuntu linux (Ubuntu Jaunty and later)
- g++ 4.3, 4.4, 4.5, 4.6, 4.7, 4.8 and 4.9
- Fedora linux
- Fedora 13: g++ 4.4
- Fedora 14: g++ 4.5
- Fedora 15: g++ 4.6
- Fedora 16: g++ 4.6
- Fedora 17: g++ 4.7.2 or later
- Fedora 18: g++ 4.7.2 or later
- Fedora 19: g++ 4.8
- Fedora 20: g++ 4.8
- Fedora 21: g++ 4.9
- Intel x86 MacOSX Snow Leopard or later
- MacPorts g++ 4.3, 4.4, 4.5, 4.6, 4.7 and 4.8
Get your copy of Just::Thread
Purchase your copy and get started with the C++11 and C++14 thread library now.
Posted by Anthony Williams
[/ news /] permanent link
Tags: multithreading, concurrency, C++0x, C++11, C++14
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Design and Content Copyright © 2005-2026 Just Software Solutions Ltd. All rights reserved. | Privacy Policy