Technical Writings
- C++ Concurrency Book
- Articles and Publications
- Conference Presentations
- Recent Blog Entries
- Multithreading Blog Entries
- C++ Blog Entries
Subscribe to Blog
Blog Archives
Blog Archive for / 2008 /
Managing Threads with a Vector
Wednesday, 10 December 2008
One of the nice things about C++0x is the support for move
semantics that comes from the new Rvalue
Reference language feature. Since this is a language feature, it
means that we can easily have types that are movable but not
copyable without resorting to std::auto_ptr-like
hackery. One such type is the new std::thread class. A
thread of execution can only be associated with one
std::thread object at a time, so std::thread
is not copyable, but it is movable — this
allows you to transfer ownership of a thread of execution between
objects, and return std::thread objects from
functions. The important point for today's blog post is that it allows
you to store std::thread objects in containers.
Move-aware containers
The C++0x standard containers are required to be move-aware, and
move objects rather than copy them when changing
their position within the container. For existing copyable types that
don't have a specific move constructor or move-assignment
operator that takes an rvalue reference this amounts to the same
thing — when a std::vector is resized, or an
element is inserted in the middle, the elements will be copied to
their new locations. The important difference is that you can now
store types that only have a move-constructor and
move-assignment operator in the standard containers because the
objects are moved rather than copied.
This means that you can now write code like:
std::vector<std::thread> v; v.push_back(std::thread(some_function));
and it all "just works". This is good news for managing multiple
threads where the number of threads is not known until run-time
— if you're tuning the number of threads to the number of
processors, using
std::thread::hardware_concurrency() for example. It also
means that you can then use the
std::vector<std::thread> with the standard library
algorithms such as std::for_each:
void do_join(std::thread& t)
{
t.join();
}
void join_all(std::vector<std::thread>& v)
{
std::for_each(v.begin(),v.end(),do_join);
}
If you need an extra thread because one of your threads is blocked
waiting for something, you can just use insert() or
push_back() to add a new thread to the
vector. Of course you can also just move threads into or
out of the vector by indexing the elements directly:
std::vector<std::thread> v(std::thread::hardware_concurrency());
for(unsigned i=0;i<v.size();++i)
{
v[i]=std::thread(do_work);
}
In fact, many of the examples in my
book use std::vector<std::thread> for managing
the threads, as it's the simplest way to do it.
Other containers work too
It's not just std::vector that's required to be
move-aware — all the other standard containers are too. This
means you can have a std::list<std::thread>, or a
std::deque<std::thread>, or even a
std::map<int,std::thread>. In fact, the whole C++0x
standard library is designed to work with move-only types such as
std::thread.
Try it out today
Wouldn't it be nice if you could try it out today, and get used to
using containers of std::thread objects without having to
wait for a C++0x compiler? Well, you can — the
0.6 beta of the just::thread C++0x
Thread Library released last Friday provides a specialization of
std::vector<std::thread> so that you can write code
like in these examples and it will work with Microsoft Visual Studio
2008. Sign up at the just::thread
Support Forum to download it today.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: threads, C++0x, vector, multithreading, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Peterson's lock with C++0x atomics
Friday, 05 December 2008
Bartosz Milewski shows an implementation of Peterson's locking algorithm in his latest post on C++ atomics and memory ordering. Dmitriy V'jukov posted an alternative implementation in the comments. Also in the comments, Bartosz says:
"So even though I don't have a formal proof, I believe my implementation of Peterson lock is correct. For all I know, Dmitriy's implementation might also be correct, but it's much harder to prove."
I'd like to offer an analysis of both algorithms to see if they are correct, below. However, before we start I'd also like to highlight a comment that Bartosz made in his conclusion:
"Any time you deviate from sequential consistency, you increase the complexity of the problem by orders of magnitude."
This is something I wholeheartedly agree with. If you weren't
convinced by my previous post on Memory
Models and Synchronization, maybe the proof below will convince
you to stick to memory_order_seq_cst (the default) unless
you really need to do otherwise.
C++0x memory ordering recap
In C++0x, we have to think about things in terms of the happens-before and synchronizes-with relationships described in the Standard — it's no good saying "it works on my CPU" because different CPUs have different default ordering constraints on basic operations such as load and store. In brief, those relationships are:
- Synchronizes-with
- An operation A synchronizes-with an
operation B if A is a store to some
atomic variable
m, with an ordering ofstd::memory_order_release, orstd::memory_order_seq_cst, B is a load from the same variablem, with an ordering ofstd::memory_order_acquireorstd::memory_order_seq_cst, and B reads the value stored by A. - Happens-before
- An operation A happens-before an
operation B if:
- A is performed on the same thread as B, and A is before B in program order, or
- A synchronizes-with B, or
- A happens-before some other operation C, and C happens-before B.
std::memory_order_consume, but this is enough for now.
If all your operations use std::memory_order_seq_cst,
then there is the additional constraint of total ordering, as I
mentioned before, but neither of the implementations in question use
any std::memory_order_seq_cst operations, so we
can leave that aside for now.
Now, let's look at the implementations.
Bartosz's implementation
I've extracted the code for Bartosz's implementation from his posts, and it is shown below:
class Peterson_Bartosz
{
private:
// indexed by thread ID, 0 or 1
std::atomic<bool> _interested[2];
// who's yielding priority?
std::atomic<int> _victim;
public:
Peterson_Bartosz()
{
_victim.store(0, std::memory_order_release);
_interested[0].store(false, std::memory_order_release);
_interested[1].store(false, std::memory_order_release);
}
void lock()
{
int me = threadID; // either 0 or 1
int he = 1 ? me; // the other thread
_interested[me].exchange(true, std::memory_order_acq_rel);
_victim.store(me, std::memory_order_release);
while (_interested[he].load(std::memory_order_acquire)
&& _victim.load(std::memory_order_acquire) == me)
continue; // spin
}
void unlock()
{
int me = threadID;
_interested[me].store(false,std::memory_order_release);
}
}
There are three things to prove with Peterson's lock:
- If thread 0 successfully acquires the lock, then thread 1 will not do so;
- If thread 0 acquires the lock and then releases it, then thread 1 will successfully acquire the lock;
- If thread 0 fails to acquire the lock, then thread 1 does so.
Let's look at each in turn.
If thread 0 successfully acquires the lock, then thread 1 will not do so
Initially _victim is 0, and the
_interested variables are both false. The
call to lock() from thread 0 will then set
_interested[0] to true, and
_victim to 0.
The loop then checks _interested[1], which is still
false, so we break out of the loop, and the lock is
acquired.
So, what about thread 1? Thread 1 now comes along and tries to
acquire the lock. It sets _interested[1] to
true, and _victim to 1, and then enters the
while loop. This is where the fun begins.
The first thing we check is _interested[0]. Now, we
know this was set to true in thread 0 as it acquired the
lock, but the important thing is: does the CPU running thread 1 know
that? Is it guaranteed by the memory model?
For it to be guaranteed by the memory model, we have to prove that
the store to _interested[0] from thread 0
happens-before the load from thread 1. This is trivially true
if we read true in thread 1, but that doesn't help: we
need to prove that we can't read false. We
therefore need to find a variable which was stored by thread 0, and
loaded by thread 1, and our search comes up empty:
_interested[1] is loaded by thread 1 as part of the
exchange call, but it is not written by thread 0, and
_victim is written by thread 1 without reading the value
stored by thread 0. Consequently, there is no ordering
guarantee on the read of _interested[0], and thread 1
may also break out of the while loop and acquire
the lock.
This implementation is thus broken. Let's now look at Dmitriy's implementation.
Dmitriy's implementation
Dmitriy posted his implementation in the comments using the syntax for his Relacy Race Detector tool, but it's trivially convertible to C++0x syntax. Here is the C++0x version of his code:
std::atomic<int> flag0(0),flag1(0),turn(0);
void lock(unsigned index)
{
if (0 == index)
{
flag0.store(1, std::memory_order_relaxed);
turn.exchange(1, std::memory_order_acq_rel);
while (flag1.load(std::memory_order_acquire)
&& 1 == turn.load(std::memory_order_relaxed))
std::this_thread::yield();
}
else
{
flag1.store(1, std::memory_order_relaxed);
turn.exchange(0, std::memory_order_acq_rel);
while (flag0.load(std::memory_order_acquire)
&& 0 == turn.load(std::memory_order_relaxed))
std::this_thread::yield();
}
}
void unlock(unsigned index)
{
if (0 == index)
{
flag0.store(0, std::memory_order_release);
}
else
{
flag1.store(0, std::memory_order_release);
}
}
So, how does this code fare?
If thread 0 successfully acquires the lock, then thread 1 will not do so
Initially the turn, flag0 and
flag1 variables are all 0. The call to
lock() from thread 0 will then set flag0 to
1, and turn to 1. These variables are essentially
equivalent to the variables in Bartosz's implementation, but
turn is set to 0 when _victim is set to 1,
and vice-versa. That doesn't affect the logic of the code.
The loop then checks flag1, which is still 0, so we
break out of the loop, and the lock is acquired.
So, what about thread 1? Thread 1 now comes along and tries to
acquire the lock. It sets flag1 to 1, and
turn to 0, and then enters the while
loop. This is where the fun begins.
As before, the first thing we check is flag0. Now, we
know this was set to 1 in thread 0 as it acquired the lock, but the
important thing is: does the CPU running thread 1 know that? Is it
guaranteed by the memory model?
Again, for it to be guaranteed by the memory model, we have to
prove that the store to flag0 from thread 0
happens-before the load from thread 1. This is trivially true
if we read 1 in thread 1, but that doesn't help: we need to prove that
we can't read 0. We therefore need to find a variable which
was stored by thread 0, and loaded by thread 1, as before.
This time our search is successful: turn is set using
an exchange operation, which is a read-modify-write
operation. Since it uses std::memory_order_acq_rel memory
ordering, it is both a load-acquire and a store-release. If the load
part of the exchange reads the value written by thread 0,
we're home dry: turn is stored with a similar
exchange operation with
std::memory_order_acq_rel in thread 0, so the store from
thread 0 synchronizes-with the load from thread 1.
This means that the store to flag0 from thread 0
happens-before the exchange on turn
in thread 1, and thus happens-before the load in
the while loop. The load in the
while loop thus reads 1 from flag0, and
proceeds to check turn.
Now, since the store to turn from thread 0
happens-before the store from thread 1 (we're relying on that
for the happens-before relationship on flag0,
remember), we know that the value to be read will be the value we
stored in thread 1: 0. Consequently, we keep looping.
OK, so if the store to turn in thread 1 reads the
value stored by thread 0 then thread 1 will stay out of the lock, but
what if it doesn't read the value store by thread 0? In this
case, we know that the exchange call from thread 0 must
have seen the value written by the exchange in thread 1
(writes to a single atomic variable always become visible in the same
order for all threads), which means that the write to
flag1 from thread 1 happens-before the read in
thread 0 and so thread 0 cannot have acquired the lock. Since this was
our initial assumption (thread 0 has acquired the lock), we're home
dry — thread 1 can only acquire the lock if thread 0 didn't.
If thread 0 acquires the lock and then releases it, then thread 1 will successfully acquire the lock
OK, so we've got as far as thread 0 acquiring the lock and thread 1
waiting. What happens if thread 0 now releases the lock? It does this
simply by writing 0 to flag0. The while loop
in thread 1 checks flag0 every time round, and breaks out
if the value read is 0. Therefore, thread 1 will eventually acquire
the mutex. Of course, there is no guarantee when it will
acquire the mutex — it might take arbitrarily long for the the
write to flag0 to make its way to thread 1, but it will
get there in the end. Since flag0 is never written by
thread 1, it doesn't matter whether thread 0 has already released the
lock when thread 1 starts waiting, or whether thread 1 is already
waiting — the while loop will still terminate, and
thread 1 will acquire the lock in both cases.
That just leaves our final check.
If thread 0 fails to acquire the lock, then thread 1 does so
We've essentially already covered this when we checked that thread
1 doesn't acquire the lock if thread 0 does, but this time we're going
in reverse. If thread 0 doesn't acquire the lock, it is because it
sees flag1 as 1 and turn as 1. Since
flag1 is only written by thread 1, if it is 1 then thread
1 must have at least called lock(). If thread 1 has
called unlock then eventually flag1 will be
read as 0, so thread 0 will acquire the lock. So, let's assume for now
that thread 1 hasn't got that far, so flag1 is still
1. The next check is for turn to be 1. This is the value
written by thread 0. If we read it as 1 then either the write to
turn from thread 1 has not yet become visible to thread
0, or the write happens-before the write by thread 0, so the
write from thread 0 overwrote the old value.
If the write from thread 1 happens-before the write from
thread 0 then thread 1 will eventually see turn as 1
(since the last write is by thread 0), and thus thread 1 will acquire
the lock. On the other hand, if the write to turn from
thread 0 happens-before the write to turn from
thread 1, then thread 0 will eventually see the turn as 0
and acquire the lock. Therefore, for thread 0 to be stuck waiting the
last write to turn must have been by thread 0, which
implies thread 1 will eventually get the lock.
Therefore, Dmitriy's implementation works.
Differences, and conclusion
The key difference between the implementations other than the
naming of the variables is which variable the exchange
operation is applied to. In Bartosz's implementation, the
exchange is applied to _interested[me],
which is only ever written by one thread for a given value of
me. In Dmitriy's implementation, the
exchange is applied to the turn variable,
which is the variable updated by both threads. It therefore acts as a
synchronization point for the threads. This is the key to the whole
algorithm — even though many of the operations in Dmitriy's
implementation use std::memory_order_relaxed, whereas
Bartosz's implementation uses std::memory_order_acquire
and std::memory_order_release everywhere, the single
std::memory_order_acq_rel on the exchange on
the right variable is enough.
I'd like to finish by repeating Bartosz's statement about relaxed memory orderings:
"Any time you deviate from sequential consistency, you increase the complexity of the problem by orders of magnitude."
Posted by Anthony Williams
[/ threading /] permanent link
Tags: concurrency, C++0x, atomics, memory model, synchronization
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Rvalue References and Perfect Forwarding in C++0x
Wednesday, 03 December 2008
One of the new features
in C++0x
is the rvalue reference. Whereas the a "normal" lvalue
reference is declared with a single ampersand &,
an rvalue reference is declared with two
ampersands: &&. The key difference is of course
that an rvalue reference can bind to an rvalue, whereas a
non-const lvalue reference cannot. This is primarily used
to support move semantics for expensive-to-copy objects:
class X
{
std::vector<double> data;
public:
X():
data(100000) // lots of data
{}
X(X const& other): // copy constructor
data(other.data) // duplicate all that data
{}
X(X&& other): // move constructor
data(std::move(other.data)) // move the data: no copies
{}
X& operator=(X const& other) // copy-assignment
{
data=other.data; // copy all the data
return *this;
}
X& operator=(X && other) // move-assignment
{
data=std::move(other.data); // move the data: no copies
return *this;
}
};
X make_x(); // build an X with some data
int main()
{
X x1;
X x2(x1); // copy
X x3(std::move(x1)); // move: x1 no longer has any data
x1=make_x(); // return value is an rvalue, so move rather than copy
}
Though move semantics are powerful, rvalue references offer more than that.
Perfect Forwarding
When you combine rvalue references with function templates you get an interesting interaction: if the type of a function parameter is an rvalue reference to a template type parameter then the type parameter is deduce to be an lvalue reference if an lvalue is passed, and a plain type otherwise. This sounds complicated, so lets look at an example:
template<typename T>
void f(T&& t);
int main()
{
X x;
f(x); // 1
f(X()); // 2
}
The function template f meets our criterion above, so
in the call f(x) at the line marked "1", the template
parameter T is deduced to be X&,
whereas in the line marked "2", the supplied parameter is an rvalue
(because it's a temporary), so T is deduced to
be X.
Why is this useful? Well, it means that a function template can
pass its arguments through to another function whilst retaining the
lvalue/rvalue nature of the function arguments by
using std::forward. This is called "perfect
forwarding", avoids excessive copying, and avoids the template
author having to write multiple overloads for lvalue and rvalue
references. Let's look at an example:
void g(X&& t); // A
void g(X& t); // B
template<typename T>
void f(T&& t)
{
g(std::forward<T>(t));
}
void h(X&& t)
{
g(t);
}
int main()
{
X x;
f(x); // 1
f(X()); // 2
h(x);
h(X()); // 3
}
This time our function f forwards its argument to a
function g which is overloaded for lvalue and rvalue
references to an X object. g will
therefore accept lvalues and rvalues alike, but overload resolution
will bind to a different function in each case.
At line "1", we pass a named X object
to f, so T is deduced to be an lvalue
reference: X&, as we saw above. When T
is an lvalue reference, std::forward<T> is a
no-op: it just returns its argument. We therefore call the overload
of g that takes an lvalue reference (line B).
At line "2", we pass a temporary to f,
so T is just plain X. In this
case, std::forward<T>(t) is equivalent
to static_cast<T&&>(t): it ensures that
the argument is forwarded as an rvalue reference. This means that
the overload of g that takes an rvalue reference is
selected (line A).
This is called perfect forwarding because the same
overload of g is selected as if the same argument was
supplied to g directly. It is essential for library
features such as std::function
and std::thread which pass arguments to another (user
supplied) function.
Note that this is unique to template functions: we can't do this
with a non-template function such as h, since we don't
know whether the supplied argument is an lvalue or an rvalue. Within
a function that takes its arguments as rvalue references, the named
parameter is treated as an lvalue reference. Consequently the call
to g(t) from h always calls the lvalue
overload. If we changed the call
to g(std::forward<X>(t)) then it would always
call the rvalue-reference overload. The only way to do this with
"normal" functions is to create two overloads: one for lvalues and
one for rvalues.
Now imagine that we remove the overload of g for
rvalue references (delete line A). Calling f with an
rvalue (line 2) will now fail to compile because you can't
call g with an rvalue. On the other hand, our call
to h with an rvalue (line 3) will still
compile however, since it always calls the lvalue-reference
overload of g. This can lead to interesting problems
if g stores the reference for later use.
Further Reading
For more information, I suggest reading the accepted rvalue reference paper and "A Brief Introduction to Rvalue References", as well as the current C++0x working draft.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: rvalue reference, cplusplus, C++0x, forwarding
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Memory Models and Synchronization
Monday, 24 November 2008
I have read a couple of posts on memory models over the couple of weeks: one from Jeremy Manson on What Volatile Means in Java, and one from Bartosz Milewski entitled Who ordered sequential consistency?. Both of these cover a Sequentially Consistent memory model — in Jeremy's case because sequential consistency is required by the Java Memory Model, and in Bartosz' case because he's explaining what it means to be sequentially consistent, and why we would want that.
In a sequentially consistent memory model, there is a single total order of all atomic operations which is the same across all processors in the system. You might not know what the order is in advance, and it may change from execution to execution, but there is always a total order.
This is the default for the new C++0x atomics, and required for
Java's volatile, for good reason — it is
considerably easier to reason about the behaviour of code that uses
sequentially consistent orderings than code that uses a more relaxed
ordering.
The thing is, C++0x atomics are only sequentially consistent by default — they also support more relaxed orderings.
Relaxed Atomics and Inconsistent Orderings
I briefly touched on the properties of relaxed atomic operations in my presentation on The Future of Concurrency in C++ at ACCU 2008 (see the slides). The key point is that relaxed operations are unordered. Consider this simple example with two threads:
#include <thread>
#include <cstdatomic>
std::atomic<int> x(0),y(0);
void thread1()
{
x.store(1,std::memory_order_relaxed);
y.store(1,std::memory_order_relaxed);
}
void thread2()
{
int a=y.load(std::memory_order_relaxed);
int b=x.load(std::memory_order_relaxed);
if(a==1)
assert(b==1);
}
std::thread t1(thread1);
std::thread t2(thread2);
All the atomic operations here are using
memory_order_relaxed, so there is no enforced
ordering. Therefore, even though thread1 stores
x before y, there is no guarantee that the
writes will reach thread2 in that order: even if
a==1 (implying thread2 has seen the result
of the store to y), there is no guarantee that
b==1, and the assert may fire.
If we add more variables and more threads, then each thread may see a different order for the writes. Some of the results can be even more surprising than that, even with two threads. The C++0x working paper features the following example:
void thread1()
{
int r1=y.load(std::memory_order_relaxed);
x.store(r1,std::memory_order_relaxed);
}
void thread2()
{
int r2=x.load(std::memory_order_relaxed);
y.store(42,std::memory_order_relaxed);
assert(r2==42);
}
There's no ordering between threads, so thread1 might
see the store to y from thread2, and thus
store the value 42 in x. The fun part comes because the
load from x in thread2 can be reordered
after everything else (even the store that occurs after it in the same
thread) and thus load the value 42! Of course, there's no guarantee
about this, so the assert may or may not fire — we
just don't know.
Acquire and Release Ordering
Now you've seen quite how scary life can be with relaxed operations, it's time to look at acquire and release ordering. This provides pairwise synchronization between threads — the thread doing a load sees all the changes made before the corresponding store in another thread. Most of the time, this is actually all you need — you still get the "two cones" effect described in Jeremy's blog post.
With acquire-release ordering, independent reads of variables written independently can still give different orders in different threads, so if you do that sort of thing then you still need to think carefully. e.g.
std::atomicx(0),y(0); void thread1() { x.store(1,std::memory_order_release); } void thread2() { y.store(1,std::memory_order_release); } void thread3() { int a=x.load(std::memory_order_acquire); int b=y.load(std::memory_order_acquire); } void thread4() { int c=x.load(std::memory_order_acquire); int d=y.load(std::memory_order_acquire); }
Yes, thread3 and thread4 have the same
code, but I separated them out to make it clear we've got two separate
threads. In this example, the stores are on separate threads, so there
is no ordering between them. Consequently the reader threads may see
the writes in either order, and you might get a==1 and
b==0 or vice versa, or both 1 or both 0. The fun part is
that the two reader threads might see opposite
orders, so you have a==1 and b==0, but
c==0 and d==1! With sequentially consistent
code, both threads must see consistent orderings, so this would be
disallowed.
Summary
The details of relaxed memory models can be confusing, even for experts. If you're writing code that uses bare atomics, stick to sequential consistency until you can demonstrate that this is causing an undesirable impact on performance.
There's a lot more to the C++0x memory model and atomic operations than I can cover in a blog post — I go into much more depth in the chapter on atomics in my book.
Posted by Anthony Williams
[/ threading /] permanent link
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
First Review of C++ Concurrency in Action
Monday, 24 November 2008
A Dean Michael Berris has just published the first review of C++ Concurrency in Action that I've seen over on his blog. Thanks for your kind words, Dean!
C++ Concurrency in Action is not yet finished, but you can buy a copy now under the Manning Early Access Program and you'll get a PDF with the current chapters (plus updates as I write new chapters) and either a PDF or hard copy of the book (your choice) when it's finished.
Posted by Anthony Williams
[/ news /] permanent link
Tags: review, C++, cplusplus, concurrency, book
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Deadlock Detection with just::thread
Wednesday, 12 November 2008
One of the biggest problems with multithreaded programming is the
possibility of deadlocks. In the excerpt from my
book published over at codeguru.com (Deadlock:
The problem and a solution) I discuss various ways of dealing with
deadlock, such as using std::lock when acquiring multiple
locks at once and acquiring locks in a fixed order.
Following such guidelines requires discipline, especially on large
code bases, and occasionally we all slip up. This is where the
deadlock detection mode of the
just::thread library comes in: if you compile your
code with deadlock detection enabled then if a deadlock occurs the
library will display a stack trace of the deadlock threads
and the locations at which the synchronization
objects involved in the deadlock were locked.
Let's look at the following simple code for an example.
#include <thread>
#include <mutex>
#include <iostream>
std::mutex io_mutex;
void thread_func()
{
std::lock_guard<std::mutex> lk(io_mutex);
std::cout<<"Hello from thread_func"<<std::endl;
}
int main()
{
std::thread t(thread_func);
std::lock_guard<std::mutex> lk(io_mutex);
std::cout<<"Hello from main thread"<<std::endl;
t.join();
return 0;
}
Now, it is obvious just from looking at the code that there's a
potential deadlock here: the main thread holds the lock on
io_mutex across the call to
t.join(). Therefore, if the main thread manages to lock
the io_mutex before the new thread does then the program
will deadlock: the main thread is waiting for thread_func
to complete, but thread_func is blocked on the
io_mutex, which is held by the main thread!
Compile the code and run it a few times: eventually you should hit the deadlock. In this case, the program will output "Hello from main thread" and then hang. The only way out is to kill the program.
Now compile the program again, but this time with
_JUST_THREAD_DEADLOCK_CHECK defined — you can
either define this in your project settings, or define it in the first
line of the program with #define. It must be defined
before any of the thread library headers are included
in order to take effect. This time the program doesn't hang —
instead it displays a message box with the title "Deadlock Detected!"
looking similar to the following:
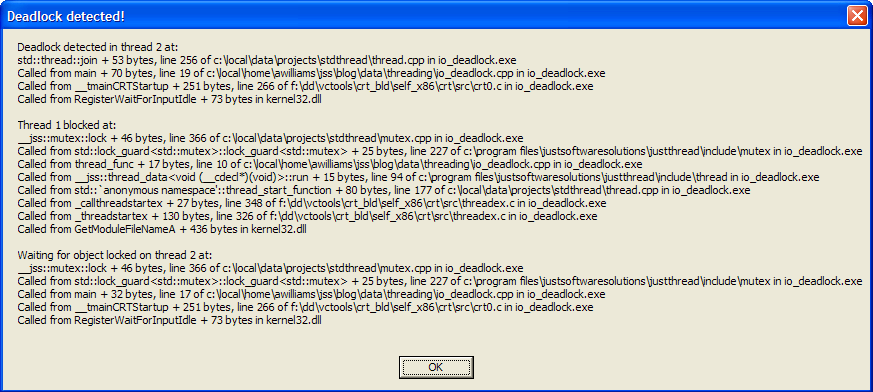
Of course, you need to have debug symbols for your executable to get meaningful stack traces.
Anyway, this message box shows three stack traces. The first is
labelled "Deadlock detected in thread 2 at:", and tells us that the
deadlock was found in the call to std::thread::join from
main, on line 19 of our source file
(io_deadlock.cpp). Now, it's important to note that "line 19" is
actually where execution will resume when join returns
rather than the call site, so in this case the call to
join is on line 18. If the next statement was also on
line 18, the stack would report line 18 here.
The next stack trace is labelled "Thread 1 blocked at:", and tells
us where the thread we're trying to join with is blocked. In this
case, it's blocked in the call to mutex::lock from the
std::lock_guard constructor called from
thread_func returning to line 10 of our source file (the
constructor is on line 9).
The final stack trace completes the circle by telling us where that
mutex was locked. In this case the label says "Waiting for object
locked on thread 2 at:", and the stack trace tells us it was the
std::lock_guard constructor in main
returning to line 17 of our source file.
This is all the information we need to see the deadlock in this case, but in more complex cases we might need to go further up the call stack, particularly if the deadlock occurs in a function called from lots of different threads, or the mutex being used in the function depends on its parameters.
The just::thread deadlock
detection can help there too: if you're running the application from
within the IDE, or you've got a Just-in-Time debugger installed then
the application will now break into the debugger. You can then use the
full capabilities of your debugger to examine the state of the
application when the deadlock occurred.
Try It Out
You can download sample Visual C++ Express 2008 project for this
example, which you can use with our just::thread
implementation of the new C++0x thread library. The code should also
work with g++.
just::thread
doesn't just work with Microsoft Visual Studio 2008 — it's also
available for g++ 4.3 on Ubuntu Linux. Get your copy
today and try out the deadlock detection feature
risk free with our 30-day money-back guarantee.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: multithreading, deadlock, c++
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Detect Deadlocks with just::thread C++0x Thread Library Beta V0.2
Saturday, 01 November 2008
I am pleased to announce that the second beta of just::thread, our C++0x Thread Library is
available, which now features deadlock detection for uses of
std::mutex. You can sign up at the just::thread Support
forum to download the beta or send an email to beta@stdthread.co.uk.
The just::thread library is a complete implementation
of the new C++0x thread library as per the current
C++0x working paper. Features include:
std::threadfor launching threads.- Mutexes and condition variables.
std::promise,std::packaged_task,std::unique_futureandstd::shared_futurefor transferring data between threads.- Support for the new
std::chronotime interface for sleeping and timeouts on locks and waits. - Atomic operations with
std::atomic. - Support for
std::exception_ptrfor transferring exceptions between threads. - New in beta 0.2: support for detecting deadlocks with
std::mutex
The library works with Microsoft Visual Studio 2008 or Microsoft Visual C++ 2008 Express for 32-bit Windows. Don't wait for a full C++0x compiler: start using the C++0x thread library today.
Sign up at the just::thread Support forum to download the beta.
Posted by Anthony Williams
[/ news /] permanent link
Tags: multithreading, concurrency, C++0x
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
just::thread C++0x Thread Library Beta V0.1 Released
Thursday, 16 October 2008
Update: just::thread was released on 8th January 2009. The just::thread C++0x thread library is currently available for purchase for Microsoft Visual Studio 2005, 2008 and 2010 for Windows and gcc 4.3, 4.4 and 4.5 for x86 Ubuntu Linux.
I am pleased to announce that just::thread, our C++0x Thread Library is now available as a beta release. You can sign up at the just::thread Support forum to download the beta or send an email to beta@stdthread.co.uk.
Currently, it only works with Microsoft Visual Studio 2008 or Microsoft Visual C++ 2008 Express for 32-bit Windows, though support for other compilers and platforms is in the pipeline.
Though there are a couple of limitations (such as the number of
arguments that can be supplied to a thread function, and the lack of
custom allocator support for std::promise), it is a
complete implementation of the new C++0x thread library as per the
current
C++0x working paper. Features include:
std::threadfor launching threads.- Mutexes and condition variables.
std::promise,std::packaged_task,std::unique_futureandstd::shared_futurefor transferring data between threads.- Support for the new
std::chronotime interface for sleeping and timeouts on locks and waits. - Atomic operations with
std::atomic. - Support for
std::exception_ptrfor transferring exceptions between threads.
Please sign up and download the beta today. The library should be going on sale by the end of November.
Please report bugs on the just::thread Support Forum or email to beta@stdthread.co.uk.
Posted by Anthony Williams
[/ news /] permanent link
Tags: multithreading, concurrency, C++0x
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
October 2008 C++ Standards Committee Mailing - New C++0x Working Paper, More Concurrency Papers Approved
Wednesday, 08 October 2008
The October 2008 mailing for the C++ Standards Committee was published today. This is a really important mailing, as it contains the latest edition of the C++0x Working Draft, which was put out as a formal Committee Draft at the September 2008 meeting. This means it is up for formal National Body voting and comments, and could in principle be the text of C++0x. Of course, there are still many issues with the draft and it will not be approved as-is, but it is "feature complete": if a feature is not in this draft it will not be in C++0x. The committee intends to fix the issues and have a final draft ready by this time next year.
Concurrency Papers
As usual, there's a number of concurrency-related papers that have been incorporated into the working draft. Some of these are from this mailing, and some from prior mailings. Let's take a look at each in turn:
- N2752: Proposed Text for Bidirectional Fences
- This paper modifies the wording for the use of fences in C++0x. It
is a new revision of N2731:
Proposed Text for Bidirectional Fences, and is the version voted
into the working paper. Now this paper has been accepted, fences are
no longer tied to specific atomic variables, but are represented by
the free functions
std::atomic_thread_fence()andstd::atomic_signal_fence(). This brings C++0x more in line with current CPU instruction sets, where fences are generally separate instructions with no associated object.std::atomic_signal_fence()just restricts the compiler's freedom to reorder variable accesses, whereasstd::atomic_thread_fence()will typically also cause the compiler to emit the specific synchronization instructions necessary to enforce the desired memory ordering. - N2782: C++ Data-Dependency Ordering: Function Annotation
- This is a revision of N2643:
C++ Data-Dependency Ordering: Function Annotation, and is the
final version voted in to the working paper. It allows functions to be
annotated with
[[carries_dependency]](using the just-accepted attributes proposal) on their parameters and return value. This can allow implementations to better-optimize code that usesstd::memory_order_consumememory ordering. - N2783: Collected Issues with Atomics
- This paper resolves LWG issues 818, 845, 846 and 864. This rewords
the descriptions of the memory ordering values to make it clear what
they mean, removes the
explicitqualification on thestd::atomic_xxxconstructors to allow implicit conversion on construction (and thus allow aggregate-style initialization), and adds simple definitions of the constructors for the atomic types (which were omitted by accident). - N2668: Concurrency Modifications to Basic String
- This has been under discussion for a while, but was finally
approved at the September meeting. The changes in this paper ensure
that it is safe for two threads to access the same
std::stringobject at the same time, provided they both perform only read operations. They also ensure that copying a string object and then modifying that copy is safe, even if another thread is accessing the original. This essentially disallows copy-on-write implementations since the benefits are now severely limited. - N2748: Strong Compare and Exchange
- This paper was in the previous mailing, and has now been
approved. In the previous working paper, the atomic
compare_exchangefunctions were allowed to fail "spuriously" even when the value of the object was equal to the comparand. This allows efficient implementation on a wider variety of platforms than otherwise, but also requires almost all uses ofcompare_exchangeto be put in a loop. Now this paper has been accepted, instead we provide two variants:compare_exchange_weakandcompare_exchange_strong. The weak variant allows spurious failure, whereas the strong variant is not allowed to fail spuriously. On architectures which provide the strong variant by default (such as x86) this would remove the need for a loop in some cases. - N2760: Input/Output Library Thread Safety
- This paper clarifies that unsynchronized access to I/O streams
from multiple threads is a data race. For most streams this means the
user is responsible for providing this synchronization. However, for
the standard stream objects (
std::cin,std::cout,std::cerrand friends) such external synchronization is only necessary if the user has calledstd::ios_base::sync_with_stdio(false). - N2775: Small library thread-safety revisions
- This short paper clarifies that the standard library functions may only access the data and call the functions that they are specified to do. This makes it easier to identify and eliminate potential data races when using standard library functions.
- N2671: An Asynchronous Future Value: Proposed Wording
- Futures are finally in C++0x! This paper from the June 2008
mailing gives us
std::unique_future<>,std::shared_future<>andstd::promise<>, which can be used for transferring the results of operations safely between threads. - N2709: Packaging Tasks for Asynchronous Execution
- Packaged Tasks are also in C++0x! This is my paper from the July
2008 mailing, which is the counterpart to N2671. A
std::packaged_task<F>is very similar to astd::function<F>except that rather than returning the result directly when it is invoked, the result is stored in the associated futures. This makes it easy to spawn functions with return values on threads, and provides a building block for thread pools.
Other Changes
The biggest change to the C++0x working paper is of course the acceptance of Concepts. There necessary changes are spread over a staggering 14 Concepts-related papers, all of which were voted in to the working draft at the September 2008 meeting.
C++0x now also has support for user-defined literals (N2765:
User-defined Literals (aka. Extensible Literals (revision 5))),
for default values of non-static data members to be
defined in the class definition (N2756:
Non-static data member initializers), and forward declaration of
enums (N2764:
Forward declaration of enumerations (rev. 3)).
Get Involved: Comment on the C++0x Draft
Please read the latest C++0x Working Draft and comment on it. If you post comments on this blog entry I'll see that the committee gets to see them, but I strongly urge you to get involved with your National Body: the only changes allowed to C++0x now are in response to official National Body comments. If you're in the UK, contact me and I'll put you in touch with the relevant people on the BSI panel.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: C++0x, C++, standards, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
"Deadlock: The Problem and a Solution" Book Excerpt Online
Wednesday, 01 October 2008
An excerpt from my book C++ Concurrency in Action
has been published on CodeGuru. Deadlock:
the Problem and a Solution describes what deadlock is and how the
std::lock() function can be used to avoid it where
multiple locks can be acquired at once. There are also some simple
guidelines for avoiding deadlock in the first place.
The C++0x library facilities mentioned in the article
(std::mutex, std::lock(),
std::lock_guard and std::unique_lock) are
all available from the Boost
Thread Library in release 1.36.0 and later.
Posted by Anthony Williams
[/ news /] permanent link
Tags: multithreading, c++, deadlock, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Implementing a Thread-Safe Queue using Condition Variables (Updated)
Tuesday, 16 September 2008
One problem that comes up time and again with multi-threaded code is how to transfer data from one thread to another. For example, one common way to parallelize a serial algorithm is to split it into independent chunks and make a pipeline — each stage in the pipeline can be run on a separate thread, and each stage adds the data to the input queue for the next stage when it's done. For this to work properly, the input queue needs to be written so that data can safely be added by one thread and removed by another thread without corrupting the data structure.
Basic Thread Safety with a Mutex
The simplest way of doing this is just to put wrap a non-thread-safe queue, and protect it with a mutex (the examples use the types and functions from the upcoming 1.35 release of Boost):
template<typename Data>
class concurrent_queue
{
private:
std::queue<Data> the_queue;
mutable boost::mutex the_mutex;
public:
void push(const Data& data)
{
boost::mutex::scoped_lock lock(the_mutex);
the_queue.push(data);
}
bool empty() const
{
boost::mutex::scoped_lock lock(the_mutex);
return the_queue.empty();
}
Data& front()
{
boost::mutex::scoped_lock lock(the_mutex);
return the_queue.front();
}
Data const& front() const
{
boost::mutex::scoped_lock lock(the_mutex);
return the_queue.front();
}
void pop()
{
boost::mutex::scoped_lock lock(the_mutex);
the_queue.pop();
}
};
This design is subject to race conditions between calls to empty, front and pop if there
is more than one thread removing items from the queue, but in a single-consumer system (as being discussed here), this is not a
problem. There is, however, a downside to such a simple implementation: if your pipeline stages are running on separate threads,
they likely have nothing to do if the queue is empty, so they end up with a wait loop:
while(some_queue.empty())
{
boost::this_thread::sleep(boost::posix_time::milliseconds(50));
}
Though the sleep avoids the high CPU consumption of a direct busy wait, there are still some obvious downsides to
this formulation. Firstly, the thread has to wake every 50ms or so (or whatever the sleep period is) in order to lock the mutex,
check the queue, and unlock the mutex, forcing a context switch. Secondly, the sleep period imposes a limit on how fast the thread
can respond to data being added to the queue — if the data is added just before the call to sleep, the thread
will wait at least 50ms before checking for data. On average, the thread will only respond to data after about half the sleep time
(25ms here).
Waiting with a Condition Variable
As an alternative to continuously polling the state of the queue, the sleep in the wait loop can be replaced with a condition
variable wait. If the condition variable is notified in push when data is added to an empty queue, then the waiting
thread will wake. This requires access to the mutex used to protect the queue, so needs to be implemented as a member function of
concurrent_queue:
template<typename Data>
class concurrent_queue
{
private:
boost::condition_variable the_condition_variable;
public:
void wait_for_data()
{
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
the_condition_variable.wait(lock);
}
}
void push(Data const& data)
{
boost::mutex::scoped_lock lock(the_mutex);
bool const was_empty=the_queue.empty();
the_queue.push(data);
if(was_empty)
{
the_condition_variable.notify_one();
}
}
// rest as before
};
There are three important things to note here. Firstly, the lock variable is passed as a parameter to
wait — this allows the condition variable implementation to atomically unlock the mutex and add the thread to the
wait queue, so that another thread can update the protected data whilst the first thread waits.
Secondly, the condition variable wait is still inside a while loop — condition variables can be subject to
spurious wake-ups, so it is important to check the actual condition being waited for when the call to wait
returns.
Be careful when you notify
Thirdly, the call to notify_one comes after the data is pushed on the internal queue. This avoids the
waiting thread being notified if the call to the_queue.push throws an exception. As written, the call to
notify_one is still within the protected region, which is potentially sub-optimal: the waiting thread might wake up
immediately it is notified, and before the mutex is unlocked, in which case it will have to block when the mutex is reacquired on
the exit from wait. By rewriting the function so that the notification comes after the mutex is unlocked, the
waiting thread will be able to acquire the mutex without blocking:
template<typename Data>
class concurrent_queue
{
public:
void push(Data const& data)
{
boost::mutex::scoped_lock lock(the_mutex);
bool const was_empty=the_queue.empty();
the_queue.push(data);
lock.unlock(); // unlock the mutex
if(was_empty)
{
the_condition_variable.notify_one();
}
}
// rest as before
};
Reducing the locking overhead
Though the use of a condition variable has improved the pushing and waiting side of the interface, the interface for the consumer
thread still has to perform excessive locking: wait_for_data, front and pop all lock the
mutex, yet they will be called in quick succession by the consumer thread.
By changing the consumer interface to a single wait_and_pop function, the extra lock/unlock calls can be avoided:
template<typename Data>
class concurrent_queue
{
public:
void wait_and_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
the_condition_variable.wait(lock);
}
popped_value=the_queue.front();
the_queue.pop();
}
// rest as before
};
Using a reference parameter to receive the result is used to transfer ownership out of the queue in order to avoid the exception
safety issues of returning data by-value: if the copy constructor of a by-value return throws, then the data has been removed from
the queue, but is lost, whereas with this approach, the potentially problematic copy is performed prior to modifying the queue (see
Herb Sutter's Guru Of The Week #8 for a discussion of the issues). This does, of
course, require that an instance Data can be created by the calling code in order to receive the result, which is not
always the case. In those cases, it might be worth using something like boost::optional to avoid this requirement.
Handling multiple consumers
As well as removing the locking overhead, the combined wait_and_pop function has another benefit — it
automatically allows for multiple consumers. Whereas the fine-grained nature of the separate functions makes them subject to race
conditions without external locking (one reason why the authors of the SGI
STL advocate against making things like std::vector thread-safe — you need external locking to do many common
operations, which makes the internal locking just a waste of resources), the combined function safely handles concurrent calls.
If multiple threads are popping entries from a full queue, then they just get serialized inside wait_and_pop, and
everything works fine. If the queue is empty, then each thread in turn will block waiting on the condition variable. When a new
entry is added to the queue, one of the threads will wake and take the value, whilst the others keep blocking. If more than one
thread wakes (e.g. with a spurious wake-up), or a new thread calls wait_and_pop concurrently, the while
loop ensures that only one thread will do the pop, and
the others will wait.
Update: As commenter David notes below, using multiple consumers does have one problem: if there are several
threads waiting when data is added, only one is woken. Though this is exactly what you want if only one item is pushed onto the
queue, if multiple items are pushed then it would be desirable if more than one thread could wake. There are two solutions to this:
use notify_all() instead of notify_one() when waking threads, or to call notify_one()
whenever any data is added to the queue, even if the queue is not currently empty. If all threads are notified then the extra
threads will see it as a spurious wake and resume waiting if there isn't enough data for them. If we notify with every
push() then only the right number of threads are woken. This is my preferred option: condition variable notify calls
are pretty light-weight when there are no threads waiting. The revised code looks like this:
template<typename Data>
class concurrent_queue
{
public:
void push(Data const& data)
{
boost::mutex::scoped_lock lock(the_mutex);
the_queue.push(data);
lock.unlock();
the_condition_variable.notify_one();
}
// rest as before
};
There is one benefit that the separate functions give over the combined one — the ability to check for an empty queue, and
do something else if the queue is empty. empty itself still works in the presence of multiple consumers, but the value
that it returns is transitory — there is no guarantee that it will still apply by the time a thread calls
wait_and_pop, whether it was true or false. For this reason it is worth adding an additional
function: try_pop, which returns true if there was a value to retrieve (in which case it retrieves it), or
false to indicate that the queue was empty.
template<typename Data>
class concurrent_queue
{
public:
bool try_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
if(the_queue.empty())
{
return false;
}
popped_value=the_queue.front();
the_queue.pop();
return true;
}
// rest as before
};
By removing the separate front and pop functions, our simple naive implementation has now become a
usable multiple producer, multiple consumer concurrent queue.
The Final Code
Here is the final code for a simple thread-safe multiple producer, multiple consumer queue:
template<typename Data>
class concurrent_queue
{
private:
std::queue<Data> the_queue;
mutable boost::mutex the_mutex;
boost::condition_variable the_condition_variable;
public:
void push(Data const& data)
{
boost::mutex::scoped_lock lock(the_mutex);
the_queue.push(data);
lock.unlock();
the_condition_variable.notify_one();
}
bool empty() const
{
boost::mutex::scoped_lock lock(the_mutex);
return the_queue.empty();
}
bool try_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
if(the_queue.empty())
{
return false;
}
popped_value=the_queue.front();
the_queue.pop();
return true;
}
void wait_and_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
the_condition_variable.wait(lock);
}
popped_value=the_queue.front();
the_queue.pop();
}
};
Posted by Anthony Williams
[/ threading /] permanent link
Tags: threading, thread safe, queue, condition variable
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
C++0x Draft and Concurrency Papers in the August 2008 Mailing
Thursday, 28 August 2008
Yesterday, the August 2008 C++ Standards Committee Mailing was published. This features a new Working Draft for C++0x, as well as quite a few other papers.
Thread-local storage
This draft incorporates N2659:
Thread-Local Storage, which was voted in at the June committee
meeting. This introduces a new keyword: thread_local
which can be used to indicate that each thread will have its own copy
of an object which would otherwise have static storage duration.
thread_local int global;
thread_local std::string constructors_allowed;
void foo()
{
struct my_class{};
static thread_local my_class block_scope_static;
}
As the example above shows, objects with constructors and
destructors can be declared thread_local. The constructor
is called (or other initialization done) before the first use of such
an object by a given thread. If the object is used on a given thread
then it is destroyed (and its destructor run) at thread exit. This is
a change from most common pre-C++0x implementations, which exclude
objects with constructors and destructors.
Additional concurrency papers
This mailing contains several papers related to concurrency and multithreading in C++0x. Some are just rationale or comments, whilst others are proposals which may well therefore be voted into the working draft at the September meeting. The papers are listed in numerical order.
- N2731: Proposed Text for Bidirectional Fences
- This is a revised version of N2633:
Improved support for bidirectional fences,
which incorporates naming changes requested by the committee at the
June meeting, along with some modifications to the memory model. In
particular, read-modify-write operations (such as
exchangeorfetch_add) that use thememory_order_relaxedordering can now feature as part of a release sequence, thus increasing the possibilities for usingmemory_order_relaxedoperations in lock-free code. Also, the definition of how fences that usememory_order_seq_cstinteract with othermemory_order_seq_cstoperations has been clarified. - N2744: Comments on Asynchronous Future Value Proposal
- This paper is a critique of N2671:
An Asynchronous Future Value: Proposed Wording. In short, the
suggestions are:
- that
shared_future<T>::get()should return by value rather than by const reference; - that
promiseobjects are copyable; - and that the
promisefunctions for setting the value and exception be overloaded with versions that return an error code rather than throwing an exception on failure.
- that
- N2745: Example POWER Implementation for C/C++ Memory Model
- This paper discusses how the C++0x memory model and atomic operations can be implemented on systems based on the POWER architecture. As a consequence, this also shows how the different memory orderings can affect the actual generated code for atomic operations.
- N2746: Rationale for the C++ working paper definition of "memory location"
- This paper is exactly what it says: a rationale for the definition
of "memory location". Basically, it discusses the reasons why every
object (even those of type
char) is a separate memory location, even though this therefore requires that memory be byte-addressable, and restricts optimizations on some architectures. - N2748: Strong Compare and Exchange
- In the current working paper, the atomic
compare_exchangefunctions are allowed to fail "spuriously" even when the value of the object was equal to the comparand. This allows efficient implementation on a wider variety of platforms than otherwise, but also requires almost all uses ofcompare_exchangeto be put in a loop. This paper proposes that instead we provide two variants:compare_exchange_weakandcompare_exchange_strong. The weak variant would be the same as the current version, whereas the strong variant would not be allowed to fail spuriously. On architectures which provide the strong variant by default (such as x86) this would remove the need for a loop in some cases.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: c++0x, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
The Intel x86 Memory Ordering Guarantees and the C++ Memory Model
Tuesday, 26 August 2008
The July 2008 version of the Intel 64 and IA-32 Architecture documents includes the information from the memory ordering white paper I mentioned before. This makes it clear that on x86/x64 systems the preferred implementation of the C++0x atomic operations is as follows (which has been confirmed in discussions with Intel engineers):
| Memory Ordering | Store | Load |
|---|---|---|
| std::memory_order_relaxed | MOV [mem],reg | MOV reg,[mem] |
| std::memory_order_acquire | n/a | MOV reg,[mem] |
| std::memory_order_release | MOV [mem],reg | n/a |
| std::memory_order_seq_cst | XCHG [mem],reg | MOV reg,[mem] |
As you can see, plain MOV is enough for even
sequentially-consistent loads if a LOCKed instruction
such as XCHG is used for the sequentially-consistent
stores.
One thing to watch out for is the Non-Temporal SSE instructions
(MOVNTI, MOVNTQ, etc.), which by their
very nature (i.e. non-temporal) don't follow the normal
cache-coherency rules. Therefore non-temporal stores must be
followed by an SFENCE instruction in order for their
results to be seen by other processors in a timely fashion.
Additionally, if you're writing drivers which deal with memory pages marked WC (Write-Combining) then additional fence instructions will be required to ensure visibility between processors. However, if you're programming with WC pages then this shouldn't be a problem.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: intel, x86, c++, threading, memory ordering, memory model
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
"Simpler Multithreading in C++0x" Article Online
Thursday, 21 August 2008
My latest article, Simpler Multithreading in C++0x is now available as part of DevX.com's Special Report on C++0x.
The article provides a whistle-stop tour of the new C++0x multithreading support.
Posted by Anthony Williams
[/ news /] permanent link
Tags: multithreading, C++0x
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Boost 1.36.0 has been Released!
Tuesday, 19 August 2008
Verson 1.36.0 of the Boost libraries was released last week. Crucially, this contains the fix for the critical bug in the win32 implementation of condition variables found in the 1.35.0 release.
There are a few other changes to the Boost.Thread library: there are now functions for acquiring multiple locks without deadlock, for example.
There are of course new libraries to try, and other libraries have been updated too. See the full Release Notes for details, or just Download the release and give it a try.
Posted by Anthony Williams
[/ news /] permanent link
Tags: boost, C++
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
C++ Concurrency in Action Early Access Edition Available
Wednesday, 13 August 2008
As those of you who attended my talk on The Future of Concurrency in C++ at ACCU 2008 (or read the slides) will know, I'm writing a book on concurrency in C++: C++ Concurrency in Action: Practical Multithreading, due to be published next year.
Those nice folks over at Manning have made it available through their Early Access Program so you can start reading without having to wait for the book to be finished. By purchasing the Early Access Edition, you will get access to each chapter as it becomes available as well as your choice of a hard copy or Ebook when the book is finished. Plus, if you have any comments on the unfinished manuscript I may be able to take them into account as I revise each chapter. Currently, early drafts of chapters 1, 3, 4 and 5 are available.
I will be covering all aspects of multithreaded programming with the new C++0x standard, from the details of the new C++0x memory model and atomic operations to managing threads and designing parallel algorithms and thread-safe containers. The book will also feature a complete reference to the C++0x Standard Thread Library.
Posted by Anthony Williams
[/ news /] permanent link
Tags: C++, concurrency, multithreading
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
July 2008 C++ Standards Committee Mailing Published
Wednesday, 30 July 2008
The July 2008 mailing for the C++ Standards
Committee was published today. Primarily this is just an update on the "state of evolution" papers, and the issue
lists. However, there are a couple of new and revised papers. Amongst them is my revised paper on packaged_task: N2709: Packaging Tasks for Asynchronous Execution.
As I mentioned when the most recent C++0x draft
was published, futures are still under discussion,
and the LWG requested that packaged_task be moved to a separate paper, with a few minor changes. N2709 is this separate paper. Hopefully the LWG will
approve this paper at the September meeting of the C++ committee in San Francisco; if they don't, then packaged_task
will join the long list of proposals that have missed the boat for C++0x.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: C++0x, C++, standards
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
How Search Engines See Keywords
Friday, 25 July 2008
Jennifer Laycock's recent post on How Search Engines See Keywords over at Search Engine Guide really surprised me. It harks back to the 1990s, with talk of keyword density, and doesn't match my understanding of modern search engines at all. It especially surprised me given the author: I felt that Jennifer was pretty savvy about these things. Maybe I'm just missing something really crucial.
Anyway, my understanding is that the search engines index each and every word on your page, and store a count of each word and phrase. If you say "rubber balls" three times, it doesn't matter if you also say "red marbles" three times: the engines don't assign "keywords" to a page, they find pages that match what the user types. This is why if I include a random phrase on a web page exactly once, and then search for that phrase then my page will likely show up in the results (assuming my phrase was sufficiently uncommon), even though other phrases might appear more often on the same page.
Once the engine has found the pages that contain the phrase that users have searched for (whether in content, or in links to that page), the search engine then ranks those pages to decide what to show. The ranking will use things like the number of times the phrase appears on the page, whether it appears in the title, in headings, links, <strong> tags or just in plain text, how many other pages link to that page with that phrase, and all the usual stuff.
Here, let's put it to the test. At the time of writing, a search on Google for "wibble flibble splodge bucket" with quotes returns no results, and a search without quotes returns just three entries. Given Google's crawl rate for my website, I expect this blog entry will turn up in the search results for that phrase within a few days, even though it only appears the once and other phrases such as "search engines" appear far more often. Of course, I may be wrong, but only time will tell.
Posted by Anthony Williams
[/ webdesign /] permanent link
Tags: seo, search engines, keywords
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Review of the Windows Installer XML (WiX) Toolset
Tuesday, 15 July 2008
A couple of weeks ago, one of the products I maintain for a client needed a new installer. This application is the server part of a client-server suite, and runs as a Service on Microsoft Windows. The old installer was built using the simple installer-builder that is part of Microsoft Visual Studio, and could not easily be extended to handle the desired functionality. Enter the WiX toolset.
As its name suggests, the Windows Installer XML Toolset is a set of tools for building Windows Installer (MSI) packages, using XML to describe the installer. At first glance, this doesn't look much easier than populating the MSI tables directly using Microsoft's Orca tool, but it's actually really straightforward, especially with the help of the WiX tutorial.
It's all about the <XML>
The perceived complexity comes from several factors. First up,
every individual file, directory and registry entry that is to be
installed must be specified as a <Component> and
given a GUID which can be used to uniquely identify that item. The
details of what to install where, combined with the inherent verbosity
of XML makes the installer build file quite large. Thankfully, being
XML, whitespace such as indenting and blank lines can be used to
separate things into logical groups, and XML comments can be used if
necessary. The installer GUI is also built using XML, which can make
things very complicated. Thankfully WiX comes with a set of
pre-designed GUIs which can be referenced from your installer build
file — you can even provide your own images in order to brand
the installer with your company logo, for example.
Once you've got over the initial shock of the XML syntax, the
toolkit is actually really easy to use. The file and directory
structure to be used by the installed application is described using
nested XML elements to mimic the directory structure, with special
predefined directory identifiers for things like the Windows
directory, the Program Files directory or the user's My Documents
folder. You can also use nested <Feature> tags to
create a tree of features which the user can choose to install (or
not) if they opt for a custom install. Each "feature" is a group of
one or more components which are identified with nested tags in the
feature tags.
Custom Actions
What if you're not just installing a simple desktop application?
Windows Installer provides support for custom actions which can be run
as part of the installation, and WiX allows you to specify
these. The old installer for the server application used custom
actions to install the service, but these weren't actually necessary
— the Windows Installer can automatically configure services, it
was just that the Visual Studio Installer builder didn't support
that. With WiX it's just a matter of adding a
<ServiceInstall> tag to one of your components.
The custom actions we did require were easy to add with the
<CustomAction> tags — you can write custom
actions as DLLs or EXEs, or even as simple VBScript included directly
in the installer build file. These can then be added to the
<InstallExecuteSequence> at the appropriate point,
taking care to specify the right conditions (such as whether to run on
install or uninstall, and whether or not to run depending on which
features are being installed).
Conclusion
The WiX toolset is very powerful, and gives you full control over everything the Windows Installer can do. Though the XML syntax is a little cumbersome, it is actually quite simple to use. Once you get used to the syntax, it is easy to see what the installer is doing, and what you need to do to get the desired effect. Though designing installer GUIs is quite hard, the supplied options will be sufficient in many cases and it is easy to customize them to your needs.
It's a free tool, so you can't beat it on price, and the tutorial really reduces the learning curve. Next time you need to build an installer, I recommend you give WiX a try.
Posted by Anthony Williams
[/ reviews /] permanent link
Tags: windows, installer, msi, wix, review
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
C++ Concurrency Papers Still Under Discussion
Monday, 07 July 2008
Last week I wrote about the new working draft of the C++0x standard and the newly-accepted concurrency papers, but I didn't mention the papers still under discussion. There's a few of those, listed below. The committee intends to publish a formal Committee Draft of the C++0x Standard at the end of the September meeting, so anything not voted into the WP at that meeting has missed the boat (though of course defects will still be fixed).
- N2671: An Asynchronous Future Value: Proposed Wording
- For those of you who've been following my postings about asynchronous
future values for C++, this is the latest proposal on
futures. Though it was discussed at the June meeting, the LWG didn't
feel it was ready to be voted in to the working draft yet. At the request of
the LWG,
packaged_taskhas been removed; I should have a separate proposal for that ready before the next meeting. - N2668: Concurrency Modifications to Basic String
- Yes, I listed this as approved last week, but I misread the
minutes of the votes: it is still under discussion. The changes in
this paper ensure that it is safe for two threads to access the same
std::stringobject at the same time, provided they both perform only read operations. They also ensure that copying a string object and then modifying that copy is safe, even if another thread is accessing the original. This essentially disallows copy-on-write implementations since the benefits are now severely limited. - N2633: Improved support for bidirectional fences
- This paper aims to simplify and improve the support for fences
(also known as memory barriers) when writing code using the new atomic
types. As the paper points out, the current
atomic_variable.fence(memory_ordering)semantics can mean that compilers have to issue stronger-than-necessary fences in many cases. By making the fences free functions that are not tied to an individual variable, they will map much better to the underlying instructions, and should lead to clearer (and more optimal) code. - N2643: C++ Data-Dependency Ordering: Function Annotation
- This paper is a counterpart to N2664:
C++ Data-Dependency Ordering: Atomics and Memory Model, and
extends the list of cases where dependencies are carried by allowing
you to annotate functions. The new style
[[annotation syntax]]is used to indicate which parameters carry a dependency into a function, and whether or not the return type carries a dependency to the call site.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: C++, concurrency, C++0x
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
New C++ Working Draft and Concurrency Papers Now Available
Friday, 04 July 2008
The post-meeting mailing following June's C++ Standards committee meeting in France is now available. This includes a new Working Draft for the C++0x standard, and a few concurrency-related papers.
From a concurrency point of view, there are several papers of interest. Firstly, a few have been accepted into the working draft, notably:
- N2661: A Foundation to Sleep On
- This paper provides a generalised time
point and duration library, which is used by the thread functions that
take times or durations. These have been updated to use these new
types and renamed to make their purpose clearer: functions that wait
for a duration are now called
xxx_for, and take a value of typestd::chrono::duration<Rep,Period>, whereas those that take absolute time points are now calledxxx_untiland take a value of typestd::chrono::time_point<Clock,Duration>. - N2668: Concurrency Modifications to Basic String
- Update: This paper has not actually been approved, I was
mistaken. Though the majority of the committee were in favour, there
was not consensus, so this paper will be discussed at a future
meeting. Thanks to Herb Sutter for
picking me up on this.
The changes in this paper ensure that it is safe for two threads to access the samestd::stringobject at the same time, provided they both perform only read operations. They also ensure that copying a string object and then modifying that copy is safe, even if another thread is accessing the original. This essentially disallows copy-on-write implementations since the benefits are now severely limited. - N2660: Dynamic Initialization and Destruction with Concurrency
- With the changes from this paper, if an application uses multiple threads then the initialization and destruction of objects with static storage duration (such as global variables) may run concurrently on separate threads. This can provide faster start-up and shut-down times for an application, but it can also introduce the possibility of race conditions where none existed previously. If you use threads in your application, it is now even more important to check the initialization order of objects with static storage duration.
- N2514: Implicit Conversion Operators for Atomics
- With this change, the atomic types such as
std::atomic_intare implicitly convertible to their corresponding fundamental types. This means, for example, that:std::atomic_int x; int y=x;
is well-formed where it wasn't previously. The implicit conversions are equivalent to calling theload()member function, and havememory_order_seq_cstordering semantics. - N2674: Shared_ptr atomic access, revision 1
- This paper introduces a new set of overloads of the free functions
for atomic operations (such as
atomic_loadandatomic_store), which operate on instances ofstd::shared_ptr<>. This allows one thread to read an instance ofstd::shared_ptrwhilst another thread is modifying that same instance if they both use the new atomic functions.
This paper also renamesatomic_swapoperations toatomic_exchange(and likewise foratomic_compare_swapand the corresponding member functions) for all atomic types, in order to avoid confusion with other types that provideswapfunctions. The atomic exchange operations only alter the value of a single object, replacing the old value with a new one, they do not exchange the values of two objects in the way thatstd::swapdoes. - N2664: C++ Data-Dependency Ordering: Atomics and Memory Model
- With the adoption of this paper the memory model gets a new
ordering option:
memory_order_consume. This is a limited form ofmemory_order_acquirewhich allows for data-dependent ordering. If a thread usesmemory_order_consume, then it is not guaranteed to see modifications to other variables made by the thread that performed the releasing operation unless those variables are accessed in conjunction with the consumed variable. This means, for example, that member variables of an object are visible if the consumed value is a pointer to that object, but that values of independent objects are not necessarily visible. This allows the compiler to perform some optimizations that are forbidden bymemory_order_acquire, and reduces the synchronization overhead on some hardware architectures. - N2678: Error Handling Specification for Chapter 30 (Threads)
- This paper brings the exceptions thrown by the thread under the
new
system_errorumbrella, with corresponding error codes and error categories. - N2669: Thread-Safety in the Standard Library (Rev 2)
- Now the standard supports threads, we need to say which standard library operations are thread-safe, and which are not. This paper basically says that non-modifying operations on the same object are safe, and any operations on separate objects are also safe. Also, separate threads may call the same library functions on separate objects without problems. As you might expect, concurrent modifications to the same object are data races and undefined behaviour.
The committee also voted to include N2659:
Thread-Local Storage in C++0x, but it doesn't appear to be in the
current draft. This paper introduces the thread_local
keyword to indicate that each thread should have its own copy of a
given object.
Finally, N2657: Local and Unnamed Types as Template Arguments has been incorporated in the working paper. Though this isn't directly concurrency related, it is something I've been campaigning for since N1427 back in 2003.
Apart from N2657, I've only listed the concurrency changes: check out the Working Draft for the C++0x standard, and the State of C++ Evolution for more details on the changes.
Posted by Anthony Williams
[/ cplusplus /] permanent link
Tags: concurrency, c++
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Condition Variable Spurious Wakes
Friday, 27 June 2008
Condition variables are a useful mechanism for waiting until an
event occurs or some "condition" is satisfied. For example, in my implementation
of a thread-safe queue I use a condition variable to avoid
busy-waiting in wait_and_pop() when the queue is
empty. However, condition variables have one "feature" which is a
common source of bugs: a wait on a condition variable may return even
if the condition variable has not been notified. This is called a
spurious wake.
Spurious wakes cannot be predicted: they are essentially random from the user's point of view. However, they commonly occur when the thread library cannot reliably ensure that a waiting thread will not miss a notification. Since a missed notification would render the condition variable useless, the thread library wakes the thread from its wait rather than take the risk.
Bugs due to spurious wakes
Consider the code for wait_and_pop from my thread-safe
queue:
void wait_and_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
the_condition_variable.wait(lock);
}
popped_value=the_queue.front();
the_queue.pop();
}
If we know that there's only one consumer thread, it would be
tempting to write this with an if instead of a
while, on the assumption that there's only one thread
waiting, so if it's been notified, the queue must not be empty:
if(the_queue.empty()) // Danger, Will Robinson
{
the_condition_variable.wait(lock);
}
With the potential of spurious wakes this is not safe: the
wait might finish even if the condition variable was not
notified. We therefore need the while, which has the
added benefit of allowing multiple consumer threads: we don't need to
worry that another thread might remove the last item from the queue,
since we're checking to see if the queue is empty before
proceeding.
That's the beginner's bug, and one that's easily overcome with a
simple rule: always check your predicate in a loop when
waiting with a condition variable. The more insidious bug
comes from timed_wait().
Timing is everything
condition_variable::wait() has a companion function
that allows the user to specify a time limit on how long they're
willing to wait: condition_variable::timed_wait(). This
function comes as a pair of overloads: one that takes an absolute
time, and one that takes a duration. The absolute time overload will
return once the clock reaches the specified time, whether or not it
was notified. The duration overload will return once the specified
duration has elapsed: if you say to wait for 3 seconds, it will stop
waiting after 3 seconds. The insidious bug comes from the overload
that takes a duration.
Suppose we wanted to add a timed_wait_and_pop()
function to our queue, that allowed the user to specify a duration to
wait. We might be tempted to write it as:
template<typename Duration>
bool timed_wait_and_pop(Data& popped_value,
Duration const& timeout)
{
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
if(!the_condition_variable.timed_wait(lock,timeout))
return false;
}
popped_value=the_queue.front();
the_queue.pop();
return true;
}
At first glance this looks fine: we're handling spurious wakes by
looping on the timed_wait() call, and we're passing the
timeout in to that call. Unfortunately, the
timeout is a duration, so every call to
timed_wait() will wait up to the specified amount of
time. If the timeout was 1 second, and the timed_wait()
call woke due to a spurious wake after 0.9 seconds, the next time
round the loop would wait for a further 1 second. In theory this could
continue ad infinitum, completely defeating the purpose of using
timed_wait() in the first place.
The solution is simple: use the absolute time overload instead. By specifying a particular clock time as the timeout, the remaining wait time decreases with each call. This requires that we determine the final timeout prior to the loop:
template<typename Duration>
bool timed_wait_and_pop(Data& popped_value,
Duration const& wait_duration)
{
boost::system_time const timeout=boost::get_system_time()+wait_duration;
boost::mutex::scoped_lock lock(the_mutex);
while(the_queue.empty())
{
if(!the_condition_variable.timed_wait(lock,timeout))
return false;
}
popped_value=the_queue.front();
the_queue.pop();
return true;
}
Though this solves the problem, it's easy to make the mistake. Thankfully, there is a better way to wait that doesn't suffer from this problem: pass the predicate to the condition variable.
Passing the predicate to the condition variable
Both wait() and timed_wait() come with
additional overloads that allow the user to specify the condition
being waited for as a predicate. These overloads encapsulate the
while loops from the examples above, and ensure that
spurious wakes are correctly handled. All that is required is that the
condition being waited for can be checked by means of a simple
function call or a function object which is passed as an additional
parameter to the wait() or timed_wait()
call.
wait_and_pop() can therefore be written like this:
struct queue_not_empty
{
std::queue<Data>& queue;
queue_not_empty(std::queue<Data>& queue_):
queue(queue_)
{}
bool operator()() const
{
return !queue.empty();
}
};
void wait_and_pop(Data& popped_value)
{
boost::mutex::scoped_lock lock(the_mutex);
the_condition_variable.wait(lock,queue_not_empty(the_queue));
popped_value=the_queue.front();
the_queue.pop();
}
and timed_wait_and_pop() can be written like this:
template<typename Duration>
bool timed_wait_and_pop(Data& popped_value,
Duration const& wait_duration)
{
boost::mutex::scoped_lock lock(the_mutex);
if(!the_condition_variable.timed_wait(lock,wait_duration,
queue_not_empty(the_queue)))
return false;
popped_value=the_queue.front();
the_queue.pop();
return true;
}
Note that what we're waiting for is the queue not to be empty — the predicate is the reverse of the condition we would put in the while loop. This will be much easier to specify when compilers implement the C++0x lambda facilities.
Conclusion
Spurious wakes can cause some unfortunate bugs, which are hard to
track down due to the unpredictability of spurious wakes. These
problems can be avoided by ensuring that plain wait()
calls are made in a loop, and the timeout is correctly calculated for
timed_wait() calls. If the predicate can be packaged as a
function or function object, using the predicated overloads of
wait() and timed_wait() avoids all the
problems.
Posted by Anthony Williams
[/ threading /] permanent link
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Comments Now Enabled - what would you like to see?
Thursday, 26 June 2008
I have now updated my blog engine to allow comments on my blog posts, so please give it a whirl.
To kick things off, please add a comment on this entry if there's something you'd like me to cover on my blog, and I'll pick the ones I feel able to write about as topics for future posts.
If you're viewing this post in an RSS reader, you'll have to actually go to the website to comment. If you're viewing this post on one of the blog directory pages, click on the title or follow the "Permanent Link" to get to the entry page.
Any comments I feel are inappropriate or spam will be deleted.
Posted by Anthony Williams
[/ news /] permanent link
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Exceptions make for Elegant Code
Friday, 06 June 2008
On this week's Stack Overflow podcast, Joel comes out quite strongly against exceptions, on the basis that they are hidden flow paths. Whilst I can sympathise with the idea of making every possible control path in a routine explicitly visible, having just had to write some C code for a recent project I would really like to say that this actually makes the code a lot harder to follow, as the actual code for what it's really doing is hidden amongst a load of error checking.
Whether or not you use exceptions, you have the same number of possible flow paths. With exceptions, the code can be a lot cleaner than with exceptions, as you don't have to write a check after every function call to verify that it did indeed succeed, and you can now proceed with the rest of the function. Instead, the code tells you when it's gone wrong by throwing an exception.
Exceptions also simplify the function signature: rather than having to add an additional parameter to hold the potential error
code, or to hold the function result (because the return value is used for the error code), exceptions allow the function signature
to specify exactly what is appropriate for the task at hand, with errors being reported "out-of-band". Yes, some functions use
errno, which helps by providing a similar out-of-band error channel, but it's not a panacea: you have to check and
clear it between every call, otherwise you might be passing invalid data into subsequent functions. Also, it requires that you have
a value you can use for the return type in the case that an error occurs. With exceptions you don't have to worry about either of
these, as they interrupt the code at the point of the error, and you don't have to supply a return value.
Here's three implementations of the same function using error code returns, errno and exceptions:
int foo_with_error_codes(some_type param1,other_type param2,result_type* result)
{
int error=0;
intermediate_type temp;
if((error=do_blah(param1,23,&temp)) ||
(error=do_flibble(param2,temp,result))
{
return error;
}
return 0;
}
result_type foo_with_errno(some_type param1,other_type param2)
{
errno=0;
intermediate_type temp=do_blah(param1,23);
if(errno)
{
return dummy_result_type_value;
}
return do_flibble(param2,temp);
}
result_type foo_with_exceptions(some_type param1,other_type param2)
{
return do_flibble(param2,do_blah(param1,23));
}
Error Recovery
In all three cases, I've assumed that there's no recovery required if do_blah succeeds but do_flibble
fails. If recovery was required, additional code would be required. It could be argued that this is where the problems with
exceptions begin, as the code paths for exceptions are hidden, and it is therefore unclear where the cleanup must be done. However,
if you design your code with exceptions in mind I find you still get elegant
code. try/catch blocks are ugly: this is where deterministic destruction comes into its own. By
encapsulating resources, and performing changes in an exception-safe manner, you end up with elegant code that behaves gracefully in
the face of exceptions, without cluttering the "happy path". Here's some code:
int foo_with_error_codes(some_type param1,other_type param2,result_type* result)
{
int error=0;
intermediate_type temp;
if(error=do_blah(param1,23,&temp))
{
return error;
}
if(error=do_flibble(param2,temp,result))
{
cleanup_blah(temp);
return error;
}
return 0;
}
result_type foo_with_errno(some_type param1,other_type param2)
{
errno=0;
intermediate_type temp=do_blah(param1,23);
if(errno)
{
return dummy_result_type_value;
}
result_type res=do_flibble(param2,temp);
if(errno)
{
cleanup_blah(temp);
return dummy_result_type_value;
}
return res;
}
result_type foo_with_exceptions(some_type param1,other_type param2)
{
return do_flibble(param2,do_blah(param1,23));
}
result_type foo_with_exceptions2(some_type param1,other_type param2)
{
blah_cleanup_guard temp(do_blah(param1,23));
result_type res=do_flibble(param2,temp);
temp.dismiss();
return res;
}
In the error code cases, we need to explicitly cleanup on error, by calling cleanup_blah. In the exception case
we've got two possibilities, depending on how your code is structured. In foo_with_exceptions, everything is just
handled directly: if do_flibble doesn't take ownership of the intermediate data, it cleans itself up. This might well
be the case if do_blah returns a type that handles its own resources, such as std::string or
boost::shared_ptr. If explicit cleanup might be required, we can write a resource management class such as
blah_cleanup_guard used by foo_with_exceptions2, which takes ownership of the effects of
do_blah, and calls cleanup_blah in the destructor unless we call dismiss to indicate that
everything is going OK.
Real Examples
That's enough waffling about made up examples, let's look at some real code. Here's something simple: adding a new value to a
dynamic array of DataType objects held in a simple dynamic_array class. Let's assume that objects of
DataType can somehow fail to be copied: maybe they allocate memory internally, which may therefore fail. We'll also use
a really dumb algorithm that reallocates every time a new element is added. This is not for any reason other than it simplifies the
code: we don't need to check whether or not reallocation is needed.
If we're using exceptions, that failure will manifest as an exception, and our code looks like this:
class DataType
{
public:
DataType(const DataType& other);
};
class dynamic_array
{
private:
class heap_data_holder
{
DataType* data;
unsigned initialized_count;
public:
heap_data_holder():
data(0),initialized_count(0)
{}
explicit heap_data_holder(unsigned max_count):
data((DataType*)malloc(max_count*sizeof(DataType))),
initialized_count(0)
{
if(!data)
{
throw std::bad_alloc();
}
}
void append_copy(DataType const& value)
{
new (data+initialized_count) DataType(value);
++initialized_count;
}
void swap(heap_data_holder& other)
{
std::swap(data,other.data);
std::swap(initialized_count,other.initialized_count);
}
unsigned get_count() const
{
return initialized_count;
}
~heap_data_holder()
{
for(unsigned i=0;i<initialized_count;++i)
{
data[i].~DataType();
}
free(data);
}
DataType& operator[](unsigned index)
{
return data[index];
}
};
heap_data_holder data;
// no copying for now
dynamic_array& operator=(dynamic_array& other);
dynamic_array(dynamic_array& other);
public:
dynamic_array()
{}
void add_element(DataType const& new_value)
{
heap_data_holder new_data(data.get_count()+1);
for(unsigned i=0;i<data.get_count();++i)
{
new_data.append_copy(data[i]);
}
new_data.append_copy(new_value);
new_data.swap(data);
}
};
On the other, if we can't use exceptions, the code looks like this:
class DataType
{
public:
DataType(const DataType& other);
int get_error();
};
class dynamic_array
{
private:
class heap_data_holder
{
DataType* data;
unsigned initialized_count;
int error_code;
public:
heap_data_holder():
data(0),initialized_count(0),error_code(0)
{}
explicit heap_data_holder(unsigned max_count):
data((DataType*)malloc(max_count*sizeof(DataType))),
initialized_count(0),
error_code(0)
{
if(!data)
{
error_code=out_of_memory;
}
}
int get_error() const
{
return error_code;
}
int append_copy(DataType const& value)
{
new (data+initialized_count) DataType(value);
if(data[initialized_count].get_error())
{
int const error=data[initialized_count].get_error();
data[initialized_count].~DataType();
return error;
}
++initialized_count;
return 0;
}
void swap(heap_data_holder& other)
{
std::swap(data,other.data);
std::swap(initialized_count,other.initialized_count);
}
unsigned get_count() const
{
return initialized_count;
}
~heap_data_holder()
{
for(unsigned i=0;i<initialized_count;++i)
{
data[i].~DataType();
}
free(data);
}
DataType& operator[](unsigned index)
{
return data[index];
}
};
heap_data_holder data;
// no copying for now
dynamic_array& operator=(dynamic_array& other);
dynamic_array(dynamic_array& other);
public:
dynamic_array()
{}
int add_element(DataType const& new_value)
{
heap_data_holder new_data(data.get_count()+1);
if(new_data.get_error())
return new_data.get_error();
for(unsigned i=0;i<data.get_count();++i)
{
int const error=new_data.append_copy(data[i]);
if(error)
return error;
}
int const error=new_data.append_copy(new_value);
if(error)
return error;
new_data.swap(data);
return 0;
}
};
It's not too dissimilar, but there's a lot of checks for error codes: add_element has gone from 10 lines to 17,
which is almost double, and there's also additional checks in the heap_data_holder class. In my experience, this is
typical: if you have to explicitly write error checks at every failure point rather than use exceptions, your code can get quite a
lot larger for no gain. Also, the constructor of heap_data_holder can no longer report failure directly: it must store
the error code for later retrieval. To my eyes, the exception-based version is a whole lot clearer and more elegant, as well as
being shorter: a net gain over the error-code version.
Conclusion
I guess it's a matter of taste, but I find code that uses exceptions is shorter, clearer, and actually has fewer bugs than code that uses error codes. Yes, you have to think about the consequences of an exception, and at which points in the code an exception can be thrown, but you have to do that anyway with error codes, and it's easy to write simple resource management classes to ensure everything is taken care of.
Posted by Anthony Williams
[/ design /] permanent link
Tags: exceptions, elegance, software
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Updated (yet again) Implementation of Futures for C++
Friday, 30 May 2008
I have updated my prototype
futures library implementation yet again. This version adds
wait_for_any() and wait_for_all() functions, which can be used either to wait for up to five futures known
at compile time, or a dynamic collection using an iterator range.
jss::unique_future<int> futures[count];
// populate futures
jss::unique_future<int>* const future=
jss::wait_for_any(futures,futures+count);
std::vector<jss::shared_future<int> > vec;
// populate vec
std::vector<jss::shared_future<int> >::iterator const f=
jss::wait_for_any(vec.begin(),vec.end());
The new version is available for download, again under the Boost Software License. It still needs to be compiled against the Boost Subversion Trunk, as it uses the Boost Exception library and some new features of the Boost.Thread library, which are not available in an official boost release.
Sample usage can be seen in the test harness. The support for alternative allocators is still missing. The documentation for the futures library is available online, but is also included in the zip file.
Please download this prototype, put it through its paces, and let me know what you think.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: futures, promise, threading, concurrency, n2561
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
C, BASIC and Real Programmers
Tuesday, 27 May 2008
There's been a lot of discussion about learning C, and whether or not BASIC provides a good grounding for learning to program, following Joel Spolsky and Jeff Atwood's Stack overflow podcasts.
Having been one of those who grew up with the first batch of home computers in the 1980s, and therefore learnt to program in BASIC on an 8-bit home-computer, I feel ideally qualified to add my tuppence to the discussion.
I think BASIC was a crucial part of my early interactions with
computers. When you turned the computer on, it sat there expectantly,
with a prompt that said Ready, and a blinking cursor
inviting you to type something. The possibilities were endless. Not
only that, but you could often view the source code of games, as many
of them were written in BASIC. This would allow you to learn from
others, and crucially hammered home the idea that you could do this
too: they were using BASIC just like you. This is a long way from the
experience of today's first-time computer users: the computer starts
up, and does all kinds of fancy things from the get-go. You don't type
in BASIC commands to make it do things, you click the mouse. Modern
computers don't even come with a programming language: you have to
install a compiler or interpreter first. I am concerned that the next
generation of programmers will be missing out because of this.
BASIC is not enough
However, BASIC is not enough. BASIC teaches you about the general
ideas of programming: variables, statements, expressions, etc., but
BASIC interpreters rarely featured much in the way of structured
programming techniques. Typically, all variables were generally
global, and there was often no such thing as a procedure or function
call: just about everything was done with GOTO or maybe
GOSUB. BASIC learnt in isolation by a lone hobbyist
programmer, by cribbing bits from manuals, magazines, and other
people's source code, would not engender much in the way of good
programming habits. Though it did serve to separate
the programming sheep from the non-programming goats, I can see
why Dijkstra was so whipping of it. To be a good programmer, BASIC is
not enough.
To learn good programming habits and really understand about the machine requires more than BASIC. For many, C is the path to such enlightenment: it provides functions and local variables, so you can learn about structured programming, and it's "close to the machine", so you have to deal with pointers and memory allocation. If you can truly grok programming in C, then it will improve your programming, whatever language you use.
I took another path. Not one that I would necessarily recommend to
others, but it certainly worked for me. You see, a home computer came
with not just one language but two: BASIC and machine
code. As time wore on, the BASIC listing of source code for games
would increasingly be a long list of DATA statements with
seemingly random sequences of the digits 0-9 and the letters A-F,
along with a few lines of BASIC, at least one of which would feature
the mysterious POKE command. This is where I learnt about
machine code and assembly language: these DATA statements
contain the hexadecimal representation of the raw instructions that
the computer executes.
Real Programmers do it in hex
Tantalized, I acquired a book on Z80 assembly language, and I was hooked. I would spend hours writing out programs on pieces of paper and converting them into hex codes by looking up the mnemonics in the reference manual. I would calculate jump offsets by counting bytes. Over time I learnt the opcodes for most of the Z80 instruction set. Real Programmers don't need an assembler and certainly not a compiler; Real programmers can do it all by hand!
These days, I use a compiler and assembler like everyone else, but my point still stands, and it is this: by learning assembly language, I had to confront the raw machine at its most basic level. Binary and hexadecimal arithmetic, pointers, subroutines, stacks and registers. Good programming techniques follow naturally: if your loop is too long, the jump instruction at the end won't reach, as there is a limit of 128 bytes on conditional jumps. Duplicate code is not just a problem for maintenance: you have to convert it twice, and it consumes twice as much of your precious address space, so subroutines become an important basic technique. By the time I learnt C, I had already learnt much of the lessons around pointers and memory allocation that you can only get from a low-level language.
It's all in the details
BASIC was an important rite of passage for many of today's programmers: those who learnt programming on their home computer in the 1980s, but it is not enough. High-level programming languages such as C# or Java are a vast improvement on BASIC, but they don't provide programmers with the low-level knowledge that can be gained by really learning C or assembler.
It's the low level details that are important here. If you don't actively program in C, you don't have to learn C per-se, but something equivalently low-level. If you find the idea of writing a whole program in assembler and machine code interesting, go with that: I thoroughly enjoyed it, but it might not be your cup of tea.
C is not enough either
This actually ties in with the whole "learn a new programming language every year" idea: different programming languages bring different ideas and concepts to the mix. I have learnt a lot from looking at how programs are written in Haskell and Lisp, even though I never use them in my work, and I learnt much from Java and C# that I didn't learn from C and assembler. The same applies here: a low level programming language such as C provides a unique perspective that higher-level languages don't provide. Viewing things from this perspective can improve your code whatever language you write in. If you're striving to write elegant software, viewing it from multiple perspectives can only help.
Posted by Anthony Williams
[/ design /] permanent link
Tags: programming languages, C, BASIC, programmers
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
The A-Z of Cool Computer Games
Tuesday, 27 May 2008

My wife picked up this book last week, and it's an absolutely fabulous book. It's a jolly, nostalgic trip down memory lane for those of us (like myself and my wife) who grew up with the first batch of home computers in the 1980s. If you can look back fondly on the touch sssssssssseeeeeeenstiiive keyboard of the ZX81, the nine (count them!) colours of the Dragon-32, the 64K (wow!) and hardware sprites of the Commodore 64, and the delights of games like Manic Miner, Frogger and Hungry Horace, then this book is for you.
This book covers more than just the games, though: there are
sections on the home computers themselves, the social environment
surrounding home computer usage, and the various paraphernalia and
random bits of gadgetry people used to have. Over time, the nature
of computer games has changed quite considerably: no longer can you
look at the source code for a game just by pressing Escape
or Break and typing LIST at the ensuing BASIC
prompt; no longer do we have to fiddle with the volume and tone
controls on our tape decks in order to get the latest game to load;
and no longer are we limited to 16 colours (or less).
If you've got a bit of time to spare, and fancy a trip down memory
lane to a youth spent destroying joysticks by playing Daley
Thompson's Decathlon too vigorously or typing in listings from
magazines only to get SYNTAX ERROR in line 4360 when
you try and run them, buy this book.
Recommended.
Buy this book
At Amazon.co.ukAt Amazon.com
Posted by Anthony Williams
[/ reviews /] permanent link
Tags: reviews, games
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Updated (again) Implementation of Futures for C++
Thursday, 15 May 2008
I have updated my prototype futures library implementation again, primarily to add documentation, but also to fix a few minor issues.
The new version is available for download, again under the Boost Software License. It still needs to be compiled against the Boost Subversion Trunk, as it uses the Boost Exception library, which is not available in an official boost release.
Sample usage can be seen in the test harness. The support for alternative allocators is still missing. The documentation for the futures library is available online, but is also included in the zip file.
Please download this prototype, put it through its paces, and let me know what you think.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: futures, promise, threading, concurrency, n2561
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Updated Implementation of Futures for C++
Sunday, 11 May 2008
I have updated my prototype futures library implementation in light of various comments received, and my own thoughts.
The new version is available for download, again under the Boost Software License. It still needs to be compiled against the Boost Subversion Trunk, as it uses the Boost Exception library, which is not available in an official boost release.
Sample usage can be seen in the test harness. The support for alternative allocators is still missing.
Changes
- I have removed the
try_get/timed_getfunctions, as they can be replaced with a combination ofwait()ortimed_wait()andget(), and they don't work withunique_future<R&>orunique_future<void>. - I've also removed the
move()functions onunique_future. Instead,get()returns an rvalue-reference to allow moving in those types with move support. Yes, if you callget()twice on a movable type then the secondget()returns an empty shell of an object, but I don't really think that's a problem: if you want to callget()multiple times, use ashared_future. I've implemented this with both rvalue-references and the boost.thread move emulation, so you can have aunique_future<boost::thread>if necessary.test_unique_future_for_move_only_udt()in test_futures.cpp shows this in action with a user-defined movable-only typeX. - Finally, I've added a
set_wait_callback()function to bothpromiseandpackaged_task. This allows for lazy-futures which don't actually run the operation to generate the value until the value is needed: no threading required. It also allows for a thread pool to do task stealing if a pool thread waits for a task that's not started yet. The callbacks must be thread-safe as they are potentially called from many waiting threads simultaneously. At the moment, I've specified the callbacks as taking a non-const reference to thepromiseorpackaged_taskfor which they are set, but I'm open to just making them be any callable function, and leaving it up to the user to callbind()to do that.
I've left the wait operations as wait() and timed_wait(), but I've had a suggestion to use
wait()/wait_for()/wait_until(), which I'm actively considering.
Please download this prototype, put it through its paces, and let me know what you think.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: futures, promise, threading, concurrency, n2561
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Free Implementation of Futures for C++ from N2561
Monday, 05 May 2008
I am happy to announce the release of a prototype futures library for C++ based on N2561. Packaged as a single header file released under the Boost Software License it needs to be compiled against the Boost Subversion Trunk, as it uses the Boost Exception library, which is not available in an official boost release.
Sample usage can be seen in the test harness. There is one feature missing, which is the support for alternative allocators. I intend to add such support in due course.
Please download this prototype, put it through its paces, and let me know what you think.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: futures, promise, threading, concurrency, n2561
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Bug Found in Boost.Thread (with Fix): Flaw in Condition Variable on Windows
Monday, 28 April 2008
There's a bug....
First the bad news: shortly after Boost
1.35.0 was released, a couple of users reported experiencing problems using
boost::condition_variable on Windows: when they used
notify_one()<\code>, sometimes their notifies disappeared, even when they
knew there was a waiting thread.
... and now it's fixed
Next, the good news: I've found and fixed the bug, and committed the fix to
the boost Subversion repository. If you can't update your boost implementation
to trunk, you can download
the new code and replace
boost/thread/win32/condition_variable.hpp from the boost 1.35.0
distribution with the new version.
What was it?
For those of you interested in the details, this bug was in code related to
detecting (and preventing) spurious wakes. When a condition variable was
notified with notify_one(), the implementation was choosing one or
more threads to compete for the notify. One of these would get the notification
and return from wait(). Those that didn't get the notify were
supposed to resume waiting without returning from
wait(). Unfortunately, this left a potential gap where those
threads weren't waiting, so would miss any calls to notify_one()
that occurred before those threads resumed waiting.
The fix was to rewrite the wait/notify mechanism so this gap no longer exists, by changing the way that waiting threads are counted.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: boost, thread, condition variable, windows
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
The Future of Concurrency in C++: Slides from ACCU 2008
Monday, 07 April 2008
My presentation on The Future of Concurrency in C++ at ACCU 2008 last Thursday went off without a hitch. I was pleased to find that my talk was well attended, and the audience had lots of worthwhile questions — hopefully I answered them to everybody's satisfaction.
For those that didn't attend, or for those that did, but would like a reminder of what I said, here are the slides from my presentation.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: concurrency, multithreading, C++, ACCU
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Boost 1.35.0 has been Released!
Tuesday, 01 April 2008
Verson 1.35.0 of the Boost libraries was released on Saturday. This release includes a major revision of the Boost.Thread library, to bring it more in line with the C++0x Thread Library. There are many new libraries, and revisions to other libraries too, see the full Release Notes for details, or just Download the release and give it a try.
Posted by Anthony Williams
[/ news /] permanent link
Tags: boost
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Optimizing Applications with Fixed-Point Arithmetic
Tuesday, 01 April 2008
My latest article, Optimizing Math-intensive Applications with Fixed Point Arithmetic from the April 2008 issue of Dr Dobb's Journal is now available online. (I originally had "Maths-intensive" in the title, being English, but they dropped the "s", being American).
In the article, I describe the fixed-point techniques I used to vastly improve the performance of an application using sines, cosines and exponentials without hardware floating point support.
The source code referenced in the article can be downloaded from here. It is released under the Boost Software License.
Posted by Anthony Williams
[/ news /] permanent link
Tags: optimization, fixed-point, maths
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Futures and Tasks in C++0x
Thursday, 27 March 2008
I had resigned myself to Thread Pools and Futures being punted to TR2 rather than C++0x, but it seems there is potential for some movement on this issue. At the meeting of WG21 in Kona, Hawaii in October 2007 it was agreed to include asynchronous future values in C++0x, whilst excluding thread pools and task launching.
Detlef Vollman has rekindled the effort, and drafted N2561: An Asynchronous Future Value with myself and
Howard Hinnant, based on a discussion including other members of the Standards Committee. This paper proposes four templates:
unique_future and shared_future, which are the asynchronous values themselves, and
packaged_task and promise, which provide ways of setting the asynchronous values.
Asynchronous future values
unique_future is very much like unique_ptr: it represents exclusive ownership of the value. Ownership
of a (future) value can be moved between unique_future instances, but no two unique_future instances can
refer to the same asynchronous value. Once the value is ready for retrieval, it is moved out of the internal storage
buffer: this allows for use with move-only types such as std::ifstream.
Similarly, shared_future is very much like shared_ptr: multiple instances can refer to the same
(future) value, and shared_future instances can be copied around. In order to reduce surprises with this usage (with
one thread moving the value through one instance at the same time as another tries to move it through another instance), the stored
value can only be accessed via const reference, so must be copied out, or accessed in place.
Storing the future values as the return value from a function
The simplest way to calculate a future value is with a packaged_task<T>. Much like std::function<T()>, this
encapsulates a callable object or function, for invoking at a later time. However, whereas std::function returns the
result directly to the caller, packaged_task stores the result in a future.
extern int some_function();
std::packaged_task<int> task(some_function);
std::unique_future<int> result=task.get_future();
// later on, some thread does
task();
// and "result" is now ready
Making a promise to provide a future value
The other way to store a value to be picked up with a unique_future or shared_future is to use a
promise, and then explicitly set the value by calling the set_value() member function.
std::promise<int> my_promise;
std::unique_future<int> result=my_promise.get_future();
// later on, some thread does
my_promise.set_value(42);
// and "result" is now ready.
Exceptional returns
Futures also support storing exceptions: when you try and retrieve the value, if there is a stored exception, that exception is
thrown rather than the value being retrieved. With a packaged_task, an exception gets stored if the wrapped function
throws an exception when it is invoked, and with a promise, you can explicitly store an exception with the
set_exception() member function.
Feedback
As the paper says, this is not a finished proposal: it is a basis for further discussion. Let me know if you have any comments.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: threading, futures, asynchronous values, C++0x, wg21
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Thread Interruption in the Boost Thread Library
Tuesday, 11 March 2008
One of the new features introduced in the upcoming 1.35.0 release of the boost thread library is support for interruption of a running thread. Similar to the Java and .NET interruption support, this allows for one thread to request another thread to stop at the next interruption point. This is the only way to explicitly request a thread to terminate that is directly supported by the Boost Thread library, though users can manually implement cooperative interruption if required.
Interrupting a thread in this way is much less dangerous than brute-force tactics such as
TerminateThread(), as such tactics can leave broken invariants and leak resources. If a thread is killed using a
brute-force method and it was holding any locks, this can also potentially lead to deadlock when another thread tries to acquire
those locks at some future point. Interruption is also easier and more reliable than rolling your own cooperative termination scheme
using mutexes, flags, condition variables, or some other synchronization mechanism, since it is part of the library.
Interrupting a Thread
A running thread can be interrupted by calling the interrupt() member function on the corresponding
boost::thread object. If the thread doesn't have a boost::thread object (e.g the initial thread of the
application), then it cannot be interrupted.
Calling interrupt() just sets a flag in the thread management structure for that thread and returns: it doesn't wait
for the thread to actually be interrupted. This is important, because a thread can only be interrupted at one of the predefined
interruption points, and it might be that a thread never executes an interruption point, so never sees the
request. Currently, the interruption points are:
boost::thread::join()boost::thread::timed_join()boost::condition_variable::wait()boost::condition_variable::timed_wait()boost::condition_variable_any::wait()boost::condition_variable_any::timed_wait()boost::this_thread::sleep()boost::this_thread::interruption_point()
When a thread reaches one of these interruption points, if interruption is enabled for that thread then it checks its
interruption flag. If the flag is set, then it is cleared, and a boost::thread_interrupted exception is thrown. If the
thread is already blocked on a call to one of the interruption points with interruption enabled when interrupt() is
called, then the thread will wake in order to throw the boost::thread_interrupted exception.
Catching an Interruption
boost::thread_interrupted is just a normal exception, so it can be caught, just like any other exception. This is
why the "interrupted" flag is cleared when the exception is thrown — if a thread catches and handles the interruption, it is
perfectly acceptable to interrupt it again. This can be used, for example, when a worker thread that is processing a series of
independent tasks — if the current task is interrupted, the worker can handle the interruption and discard the task, and move
onto the next task, which can then in turn be interrupted. It also allows the thread to catch the exception and terminate itself by
other means, such as returning error codes, or translating the exception to pass through module boundaries.
Disabling Interruptions
Sometimes it is necessary to avoid being interrupted for a particular section of code, such as in a destructor where an exception
has the potential to cause immediate process termination. This is done by constructing an instance of
boost::this_thread::disable_interruption. Objects of this class disable interruption for the thread that created them on
construction, and restore the interruption state to whatever it was before on destruction:
void f()
{
// interruption enabled here
{
boost::this_thread::disable_interruption di;
// interruption disabled
{
boost::this_thread::disable_interruption di2;
// interruption still disabled
} // di2 destroyed, interruption state restored
// interruption still disabled
} // di destroyed, interruption state restored
// interruption now enabled
}
The effects of an instance of boost::this_thread::disable_interruption can be temporarily reversed by constructing
an instance of boost::this_thread::restore_interruption, passing in the
boost::this_thread::disable_interruption object in question. This will restore the interruption state to what it was
when the boost::this_thread::disable_interruption object was constructed, and then disable interruption again when the
boost::this_thread::restore_interruption object is destroyed:
void g()
{
// interruption enabled here
{
boost::this_thread::disable_interruption di;
// interruption disabled
{
boost::this_thread::restore_interruption ri(di);
// interruption now enabled
} // ri destroyed, interruption disabled again
{
boost::this_thread::disable_interruption di2;
// interruption disabled
{
boost::this_thread::restore_interruption ri2(di2);
// interruption still disabled
// as it was disabled when di2 constructed
} // ri2 destroyed, interruption still disabled
} //di2 destroyed, interruption still disabled
} // di destroyed, interruption state restored
// interruption now enabled
}
boost::this_thread::disable_interruption and boost::this_thread::restore_interruption cannot be moved
or copied, and they are the only way of enabling and disabling interruption. This ensures that the interruption state is correctly
restored when the scope is exited (whether normally, or by an exception), and that you cannot enable interruptions in the middle of
an interruption-disabled block unless you're in full control of the code, and have access to the
boost::this_thread::disable_interruption instance.
At any point, the interruption state for the current thread can be queried by calling
boost::this_thread::interruption_enabled().
Cooperative Interruption
As well as the interruption points on blocking operations such as sleep() and join(), there is one
interruption point explicitly designed to allow interruption at a user-designated point in the
code. boost::this_thread::interruption_point() does nothing except check for an interruption, and can therefore be used
in long-running code that doesn't execute any other interruption points, in order to allow for cooperative interruption. Just like
the other interruption points, interruption_point() respects the interruption enabled state, and does nothing if
interruption is disabled for the current thread.
Interruption is Not Cancellation
On POSIX platforms, threads can be cancelled rather than killed, by calling pthread_cancel(). This is similar to interruption, but is a separate mechanism, with different behaviour. In particular,
cancellation cannot be stopped once it is started: whereas interruption just throws an exception, once a cancellation request has
been acknowledged the thread is effectively dead. pthread_cancel() does not always execute destructors either (though
it does on some platforms), as it is primarily a C interface — if you want to clean up your resources when a thread is
cancelled, you need to use pthread_cleanup_push() to register a cleanup handler. The advantage here is that
pthread_cleanup_push() works in C stack frames, whereas exceptions don't play nicely in C: on some platforms it will
crash your program for an exception to propagate into a C stack frame.
For portable code, I recommend interruption over cancellation. It's supported on all platforms that can use the Boost Thread library, and it works well with C++ code — it's just another exception, so all your destructors and catch blocks work just fine.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: thread, boost, interruption, concurrency, cancellation, multi-threading
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Acquiring Multiple Locks Without Deadlock
Monday, 03 March 2008
In a software system with lots of fine-grained mutexes, it can sometimes be necessary to acquire locks on more than one mutex
together in order to perform some operation. If this is not done with care, then there is the possibility of deadlock, as multiple
threads may lock the same mutexes in a different order. It is for this reason that the thread library coming with C++0x will include
a lock() function for locking multiple mutexes together: this article describes the implementation details behind such
a function.
Choose the lock order by role
The easiest way to deal with this is to always lock the mutexes in the same order. This is especially easy if the order can be hard-coded, and some uses naturally lend themselves towards this choice. For example, if the mutexes protect objects with different roles, it is relatively easy to always lock the mutex protecting one set of data before locking the other one. In such a situation, Lock hierarchies can be used to enforce the ordering — with a lock hierarchy, a thread cannot acquire a lock on a mutex with a higher hierarchy level than any mutexes currently locked by that thread.
If it is not possible to decide a-priori which mutex to lock first, such as when the mutexes are associated with the same sort of data, then a more complicated policy must be applied.
Choose the lock order by address
The simplest technique in these cases is to always lock the mutexes in ascending order of address (examples use the types and functions from the upcoming 1.35 release of Boost), like this:
void lock(boost::mutex& m1,boost::mutex& m2)
{
if(&m1<&m2)
{
m1.lock();
m2.lock();
}
else
{
m2.lock();
m1.lock();
}
}
This works for small numbers of mutexes, provided this policy is maintained throughout the application, but if several mutexes must be locked together, then calculating the ordering can get complicated, and potentially inefficient. It also requires that the mutexes are all of the same type. Since there are many possible mutex and lock types that an application might choose to use, this is a notable disadvantage, as the function must be written afresh for each possible combination.
Order mutexes "naturally", with try-and-back-off
If the mutexes cannot be ordered by address (for whatever reason), then an alternative scheme must be found. One such scheme is to use a try-and-back-off algorithm: try and lock each mutex in turn; if any cannot be locked, unlock the others and start again. The simplest implementation for 3 mutexes looks like this:
void lock(boost::mutex& m1,boost::mutex& m2,boost::mutex& m3)
{
do
{
m1.lock();
if(m2.try_lock())
{
if(m3.try_lock())
{
return;
}
m2.unlock();
}
m1.unlock();
}
while(true);
}
Wait for the failed mutex
The big problem with this scheme is that it always locks the mutexes in the same order. If m1 and m2
are currently free, but m3 is locked by another thread, then this thread will repeatedly lock m1 and
m2, fail to lock m3 and unlock m1 and m2. This just wastes CPU cycles for no
gain. Instead, what we want to do is block waiting for m3, and try to acquire the others only when
m3 has been successfully locked by this thread. For three mutexes, a first attempt looks like this:
void lock(boost::mutex& m1,boost::mutex& m2,boost::mutex& m3)
{
unsigned lock_first=0;
while(true)
{
switch(lock_first)
{
case 0:
m1.lock();
if(m2.try_lock())
{
if(m3.try_lock())
return;
lock_first=2;
m2.unlock();
}
else
{
lock_first=1;
}
m1.unlock();
break;
case 1:
m2.lock();
if(m3.try_lock())
{
if(m1.try_lock())
return;
lock_first=0;
m3.unlock();
}
else
{
lock_first=2;
}
m2.unlock();
break;
case 2:
m3.lock();
if(m1.try_lock())
{
if(m2.try_lock())
return;
lock_first=1;
m1.unlock();
}
else
{
lock_first=0;
}
m3.unlock();
break;
}
}
}
Simplicity and Robustness
This code is very long-winded, with all the duplication between the case blocks. Also, it assumes that the mutexes
are all boost::mutex, which is overly restrictive. Finally, it assumes that the try_lock calls don't throw
exceptions. Whilst this is true for the Boost mutexes, it is not required to be true in general, so a more robust implementation
that allows the mutex type to be supplied as a template parameter will ensure that any exceptions thrown will leave all the mutexes
unlocked: the unique_lock template will help with that by providing RAII locking. Taking all this into account leaves
us with the following:
template<typename MutexType1,typename MutexType2,typename MutexType3>
unsigned lock_helper(MutexType1& m1,MutexType2& m2,MutexType3& m3)
{
boost::unique_lock<MutexType1> l1(m1);
boost::unique_lock<MutexType2> l2(m2,boost::try_to_lock);
if(!l2)
{
return 1;
}
if(!m3.try_lock())
{
return 2;
}
l2.release();
l1.release();
return 0;
}
template<typename MutexType1,typename MutexType2,typename MutexType3>
void lock(MutexType1& m1,MutexType2& m2,MutexType3& m3)
{
unsigned lock_first=0;
while(true)
{
switch(lock_first)
{
case 0:
lock_first=lock_helper(m1,m2,m3);
if(!lock_first)
return;
break;
case 1:
lock_first=lock_helper(m2,m3,m1);
if(!lock_first)
return;
lock_first=(lock_first+1)%3;
break;
case 2:
lock_first=lock_helper(m3,m1,m2);
if(!lock_first)
return;
lock_first=(lock_first+2)%3;
break;
}
}
}
This code is simultaneously shorter, simpler and more general than the previous implementation, and is robust in the face of
exceptions. The lock_helper function locks the first mutex, and then tries to lock the other two in turn. If either of
the try_locks fail, then all currently-locked mutexes are unlocked, and it returns the index of the mutex than couldn't
be locked. On success, the release members of the unique_lock instances are called to release ownership of
the locks, and thus stop them automatically unlocking the mutexes during destruction, and 0 is returned. The outer
lock function is just a simple wrapper around lock_helper that chooses the order of the mutexes so that
the one that failed to lock last time is tried first.
Extending to more mutexes
This scheme can also be easily extended to handle more mutexes, though the code gets unavoidably longer, since there are more cases to handle — this is where the C++0x variadic templates will really come into their own. Here's the code for locking 5 mutexes together:
template<typename MutexType1,typename MutexType2,typename MutexType3,
typename MutexType4,typename MutexType5>
unsigned lock_helper(MutexType1& m1,MutexType2& m2,MutexType3& m3,
MutexType4& m4,MutexType5& m5)
{
boost::unique_lock<MutexType1> l1(m1);
boost::unique_lock<MutexType2> l2(m2,boost::try_to_lock);
if(!l2)
{
return 1;
}
boost::unique_lock<MutexType3> l3(m3,boost::try_to_lock);
if(!l3)
{
return 2;
}
boost::unique_lock<MutexType4> l2(m4,boost::try_to_lock);
if(!l4)
{
return 3;
}
if(!m5.try_lock())
{
return 4;
}
l4.release();
l3.release();
l2.release();
l1.release();
return 0;
}
template<typename MutexType1,typename MutexType2,typename MutexType3,
typename MutexType4,typename MutexType5>
void lock(MutexType1& m1,MutexType2& m2,MutexType3& m3,
MutexType4& m4,MutexType5& m5)
{
unsigned const lock_count=5;
unsigned lock_first=0;
while(true)
{
switch(lock_first)
{
case 0:
lock_first=lock_helper(m1,m2,m3,m4,m5);
if(!lock_first)
return;
break;
case 1:
lock_first=lock_helper(m2,m3,m4,m5,m1);
if(!lock_first)
return;
lock_first=(lock_first+1)%lock_count;
break;
case 2:
lock_first=lock_helper(m3,m4,m5,m1,m2);
if(!lock_first)
return;
lock_first=(lock_first+2)%lock_count;
break;
case 3:
lock_first=lock_helper(m4,m5,m1,m2,m3);
if(!lock_first)
return;
lock_first=(lock_first+3)%lock_count;
break;
case 4:
lock_first=lock_helper(m5,m1,m2,m3,m4);
if(!lock_first)
return;
lock_first=(lock_first+4)%lock_count;
break;
}
}
}
Final Code
The final code for acquiring multiple locks
provides try_lock and lock functions for 2 to 5 mutexes. Though the try_lock functions are
relatively straight-forward, their existence makes the lock_helper functions slightly simpler, as they can just defer
to the appropriate overload of try_lock to cover all the mutexes beyond the first one.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: threading, concurrency, mutexes, locks
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Thread Library Now in C++0x Working Draft
Monday, 11 February 2008
The latest proposal for the C++ standard thread library has finally made it into the C++0x working draft.
Woohoo!
There will undoubtedly be minor changes as feedback comes in to the committee, but this is the first real look at what C++0x thread support will entail, as approved by the whole committee. The working draft also includes the new C++0x memory model, and atomic types and operations. This means that for the first time, C++ programs will legitimately be able to spawn threads without immediately straying into undefined behaviour. Not only that, but the memory model has been very carefully thought out, so it should be possible to write even low-level stuff such as lock-free containers in Standard C++.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: threading, C++, C++0x, news
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Database Tip: Eliminate Duplicate Data
Friday, 25 January 2008
Storing duplicated data in your database is a bad idea for several reasons:
- The duplicated data occupies more space — if you store two copies of the same data in your database, it takes twice as much space.
- If duplicated data is updated, it must be changed in more than one place, which is more complex and may require more code than just changing it in one location.
- Following on from the previous point — if data is duplicated, then it is easy to miss one of the duplicates when updating, leading to different copies having different information. This may lead to confusion, and errors further down the line.
Coincidental Duplication
It is worth noting that some duplication is coincidental — it is worth checking out whether a particular instance of duplication is coincidental or not before eliminating it. For example it is common for a billing address to be the same as a delivery address, and it may be that for all existing entries in the table it is the same, but they are still different concepts, and therefore need to be handled as such (though you may manage to eliminate the duplicate storage where they are the same).
Duplication Between Tables
One of the benefits of Using an artificial primary key is that you can avoid duplication of data between the master table and those tables which have foreign keys linked to that table. This reduces the problems described above where the duplication is in the foreign key, but is only the first step towards eliminating duplication within a given table.
If there is duplication of data between tables that is not due to foreign key constraints, and is not coincidental duplication, then it is possibly worth deleting one of the copies, or making both copies reference the same row in a new table.
Duplication Between Rows Within a Table
Typically duplication between rows occurs through the use of a composite primary key, along with auxiliary data. For example, a table of customer orders might include the full customer data along with each order entry:
| CUSTOMER_ORDERS | ||||
|---|---|---|---|---|
| CUSTOMER_NAME | CUSTOMER_ADDRESS | ORDER_NUMBER | ITEM | QUANTITY |
| Sprockets Ltd | Booth Ind Est, Boston | 200804052 | Widget 23 | 450 |
| Sprockets Ltd | Booth Ind Est, Boston | 200804052 | Widget Connector | 900 |
| Foobar Inc | Baz Street, London | 200708162 | Widget Screw size 5 | 220 |
| Foobar Inc | Baz Street, London | 200708162 | Widget 42 | 55 |
In order to remove duplication between rows, the data needs to split into two tables: the duplicated data can be stored as a single row in one table, referenced by a foreign key from the other table. So, the above example could be split into two tables: a CUSTOMER_ORDERS table, and an ORDER_ITEMS table:
| CUSTOMER_ORDERS | ||
|---|---|---|
| CUSTOMER_NAME | CUSTOMER_ADDRESS | ORDER_NUMBER |
| Sprockets Ltd | Booth Ind Est, Boston | 200804052 |
| Foobar Inc | Baz Street, London | 200708162 |
| ORDER_ITEMS | ||
|---|---|---|
| ORDER_NUMBER | ITEM | QUANTITY |
| 200804052 | Widget 23 | 450 |
| 200804052 | Widget Connector | 900 |
| 200708162 | Widget Screw size 5 | 220 |
| 200708162 | Widget 42 | 55 |
The ORDER_NUMBER column would be the primary key of the CUSTOMER_ORDERS table, and a foreign key in the ORDER_ITEMS table. This isn't the only duplication in the original table, though — what if one customer places multiple orders? In this case, not only are the customer details duplicated for every item on an order, they are duplicated for every item on every order by that customer. This duplication is still present in the new schema, but in this case it is a business decision whether to keep it — if a customer changes address, do you update the old orders with the new address, or do you leave those entries alone, since that was the address that order was delivered to? If the delivered-to address is important, then this is coincidental duplication as described above, if not, then it too can be eliminated by splitting the CUSTOMER_ORDERS table into two.
The Downsides of Eliminating Duplication
The benefits of eliminating duplication might seem obvious, but there are potential downsides too. For example:
- If the application is already released, you need to provide upgrade code to change existing databases over to the new schema without losing any data.
- If you split tables in order to reduce duplication, your SQL can get more complicated, as you need more table joins.
Conclusion
As with everything in software development it's a trade-off. However, as the database gets larger, and more data gets stored, the costs of storing duplicate data increase, as do the costs of changing the schema of an existing database. For this reason, I believe that it is worth designing your schema to eliminate duplication as soon as possible — preferably before there's any data in it!
Posted by Anthony Williams
[/ database /] permanent link
Tags: database, duplication
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
The Most Popular Articles of 2007
Monday, 14 January 2008
Now we're getting into 2008, here's a list of the 10 most popular articles on the Just Software Solutions website for 2007:
- Implementing drop-down menus in pure CSS (no JavaScript)
How to implement drop-down menus in CSS in a cross-browser fashion (with a teensy bit of JavaScript for IE). - Elegance in Software and Elegance in
Software part 2
What makes software elegant? - Reduce Bandwidth Usage by Supporting
If-Modified-Sincein PHP
Optimize your website by allowing browsers to cache pages that haven't changed - Introduction to C++ Templates (PDF)
How to use and write C++ templates. - Using CSS to Replace Text with Images
How to use CSS to display titles and logos as images whilst allowing search engines and users with text-only browsers to see the text. - Testing on Multiple Platforms with VMWare
The benefits of using VMWare for testing your code or website on multiple platforms - 10 Years of Programming with POSIX Threads
A review of "Programming with POSIX Threads" by David Butenhof, 10 years after publication. - Review of Test Driven Development — A Practical
Guide, by Dave Astels
This book will help you to learn TDD. - Implementing Synchronization Primitives for Boost on Windows Platforms
The technical details behind the current implementation ofboost::mutexon Windows. - Building on a Legacy
How to handle legacy code.
Posted by Anthony Williams
[/ news /] permanent link
Tags: popular, articles
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
The Future of Concurrency in C++: ACCU 2008
Monday, 07 January 2008
I am pleased to start 2008 with some good news: I will be speaking on "The Future of Concurrency in C++" at ACCU 2008.
Here's the synopsis:
With the next version of the C++ Standard (C++0x), concurrency support is being added to C++. This means a new memory model with support for multiple threads of execution and atomic operations, and a new set of library classes and functions for managing threads and synchronizing data. There are also further library enhancements planned for the next technical report (TR2). This talk will provide an overview of the new facilities, including an introduction to the new memory model, and an in-depth look at how to use the new library. Looking forward to TR2, this talk will cover the proposed library extensions, and how facilities like futures will affect the programming model.
I hope to see you there!
Posted by Anthony Williams
[/ news /] permanent link
Tags: news, concurrency, threading, accu
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Design and Content Copyright © 2005-2026 Just Software Solutions Ltd. All rights reserved. | Privacy Policy