Technical Writings
- C++ Concurrency Book
- Articles and Publications
- Conference Presentations
- Recent Blog Entries
- Multithreading Blog Entries
- C++ Blog Entries
Subscribe to Blog
Blog Archives
Multithreading and Concurrency
My book, C++ Concurrency in Action contains a detailed description of the C++11 threading facilities, and techniques for designing concurrent code.
The just::thread implementation of the new
C++11 and C++14 thread library is available for Microsoft
Visual Studio 2005, 2008, 2010, 2012, 2013 and 2015, and TDM gcc 4.5.2, 4.6.1 and 4.8.1 on Windows, g++ 4.3, 4.4, 4.5, 4.6, 4.7, 4.8 and 4.9 on Linux, and MacPorts g++ 4.3, 4.4, 4.5, 4.6, 4.7 and 4.8 on MacOSX. Order your copy today.
Wrapping Callbacks with Futures
Friday, 03 February 2017
Libraries the perform time-consuming operations, or network-based operations, often provide a means of running the task asynchronously, so that your code can continue with other things while this operation is performed in the background.
Such functions often allow you to provide a callback which is invoked when the operation has completed. The result of the operation may be supplied directly to the callback, or the callback might be expected to make further calls into the library to detect the result.
Either way, though it is a useful facility, it doesn't work well with code that needs to wait for the result — for this, you need something that can be waited on. Futures are an ideal such mechanism, because they provide a common mechanism for waiting that is abstracted away from the details of this specific library. They also allow the result to be transferred directly to the waiting thread, again abstracting away the details.
So, what do you do if the library you want to use provides a callback facility, and not a future-based wait facility? You wrap the callback in a future.
Promises, promises
The key to wrapping a callback in a future is the promise. A promise is the producer side of a future: you set the value through the promise in order to consume it via the future.
In C++, promises are provided through the std::promise class template; the
template parameter specifies the type of the data being transferred, and thus is
the same as the template parameter of the std::future that you will eventually
be returning to the user. When you call prom.set_value() on some promise
prom, then the corresponding future (retrieved by calling prom.get_future())
will become ready, holding the relevant value.
Promises and futures are not unique to C++; they are available in at least JavaScript, Python, Java and Scala, and pretty much any modern concurrency library for any language will have something that is equivalent. Adapting the examples to your favourite language is left as an exercise for the reader.
Simple callbacks
The most convenient case for us when trying to wrap a function that takes a
callback is where the function we are calling takes anything that is callable as
the callback. In C++ this might be represented as an instantiation of
std::function. e.g.
class request_data;
class retrieved_data;
void async_retrieve_data(
request_data param,
std::function<void(retrieved_data)> callback);What we need to do to wrap this is the following:
- Create a promise.
- Get the future from the promise.
- Construct a callable object that can hold the promise, and will set the value on the promise when called.
- Pass that object as the callback.
- Return the future that we obtained in step 2.
This is the same basic set of steps as we'll be doing in all the examples that follow; it is the details that will differ.
Note: std::function requires that the callable object it wraps is copyable (so
that if the std::function object itself is copied, it can copy the wrapped
callable object), so we cannot hold the std::promise itself by value, as
promises are not copyable.
We can thus write this using a C++ lambda as the callable object:
std::future<retrieved_data> wrapped_retrieve_data(request_data param) {
std::shared_ptr<std::promise<retrieved_data>> prom=
std::make_shared<std::promise<retrieved_data>>();
std::future<retrieved_data> res=prom->get_future();
async_retrieve_data(
param,
[prom](retrieved_data result){
prom->set_value(result);
});
return res;
}Here, we're using a std::shared_ptr to provide a copyable wrapper for the
promise, so that it can be copied into the lambda, and the lambda itself will be
copyable. When the copy of the lambda is called, it sets the value on the
promise through its copy of the std::shared_ptr, and the future that is
returned from wrapped_retrieve_data will become ready.
That's all very well if the function uses something like std::function for the
callback. However, in practice that's not often the case. More often you have
something that takes a plain function and a parameter to pass to this function;
an approach inherited from C. Indeed, many APIs that you might wish to wrap are
C APIs.
Plain function callbacks with a user_data parameter
A function that takes a plain function for the callback and a user_data
parameter to pass to the function often looks something like this:
void async_retrieve_data(
request_param param,
void (*callback)(uintptr_t user_data,retrieved_data data),
uintptr_t user_data);The user_data you supply to async_retrieve_data is passed as the first
parameter of your callback when the data is ready.
In this case, wrapping out callback is a bit more tricky, as we cannot just pass
our lambda directly. Instead, we must create an object, and pass something to
identify that object via the user_data parameter. Since our user_data is
uintptr_t, it is large enough to hold a pointer, so we can cast the pointer to
our object to uintptr_t, and pass it as the user_data. Our callback can then
cast it back before using it. This is a common approach when passing C++ objects
through C APIs.
The issue is: what object should we pass a pointer to, and how will its lifetime be managed?
One option is to just allocate our std::promise on the heap, and pass the
pointer to that:
void wrapped_retrieve_data_callback(uintptr_t user_data,retrieved_data data) {
std::unique_ptr<std::promise<retrieved_data>> prom(
reinterpret_cast<std::promise<retrieved_data>*>(user_data));
prom->set_value(data);
}
std::future<retrieved_data> wrapped_retrieve_data(request_data param) {
std::unique_ptr<std::promise<retrieved_data>> prom=
std::make_unique<std::promise<retrieved_data>>();
std::future<retrieved_data> res=prom->get_future();
async_retrieve_data(
param,
wrapped_retrieve_data_callback,
reinterpret_cast<uintptr_t>(prom->get()));
prom.release();
return res;
}Here, we use std::make_unique to construct our promise, and give us a
std::unique_ptr pointing to it. We then get the future as before, and call the
function we're wrapping, passing in the raw pointer, cast to an integer. We then
call release on our pointer, so the object isn't deleted when we return from
the function.
In our callback, we then cast the user_data parameter back to a pointer, and
construct a new std::unique_ptr object to take ownership of it, and ensure it
gets deleted. We can then set the value on our promise as before.
This is a little bit more convoluted than the lamda version from before, but it
works in more cases. Often the APIs will take a void* rather than a
uintptr_t, in which case you only need a static_cast rather than the scary
reinterpret_cast, but the structure is the same.
An alternative to heap-allocating the promise directly is to store it in a
global container (e.g. a std::list<std::promise<T>>), provided that its address
can't change. You then need to ensure that it gets destroyed at a suitable
point, otherwise you'll end up with a container full of used promises.
If you've only got C++11 futures, then the advantages to wrapping the callback-based API like so is primarily about abstracting away the interface, and providing a means of waiting for the result. However, if your library provides the extended futures from the C++ Concurrency TS then you can benefit from continuations to add additional functions to call when the data is ready, without having to modify the callback.
Summary
Wrapping asynchronous functions that take callbacks with futures provides a nice abstraction boundary to separate the details of the API call from the rest of your code. It is a common pattern in all languages that provide the future/promise abstraction, especially where that abstraction allows for continuations.
If you have any thoughts on this, let me know in the comments below.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: callbacks, async, futures, threading, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Why do we need atomic_shared_ptr?
Friday, 21 August 2015
One of the new class templates provided in the upcoming
Concurrency TS
is
atomic_shared_ptr,
along with its counterpart atomic_weak_ptr. As you might guess, these are the
std::shared_ptr and std::weak_ptr equivalents of std::atomic<T*>, but why
would one need them? Doesn't std::shared_ptr already have to synchronize the
reference count?
std::shared_ptr and multiple threads
std::shared_ptr works great in multiple threads, provided each thread has its
own copy or copies. In this case, the changes to the reference count are indeed
synchronized, and everything just works, provided of course that what you do
with the shared data is correctly synchronized.
class MyClass;
void thread_func(std::shared_ptr<MyClass> sp){
sp->do_stuff();
std::shared_ptr<MyClass> sp2=sp;
do_stuff_with(sp2);
}
int main(){
std::shared_ptr<MyClass> sp(new MyClass);
std::thread thread1(thread_func,sp);
std::thread thread2(thread_func,sp);
thread2.join();
thread1.join();
}In this example, you need to ensure that it is safe to call
MyClass::do_stuff() and do_stuff_with() from multiple threads concurrently
on the same instance, but the reference counts are handled OK.
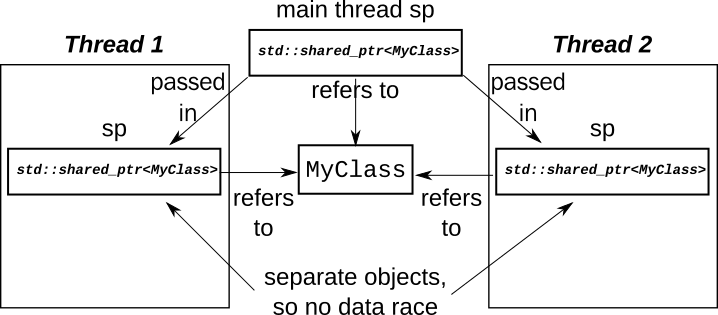
The problems come when you try and share a single std::shared_ptr instance
between threads.
Sharing a std::shared_ptr instance between threads
I could provide a trivial example of a std::shared_ptr instance shared between
threads, but instead we'll look at something a little more interesting, to give
a better feel for why you might need it.
Consider for a moment a simple singly-linked list, where each node holds a pointer to the next:
class MyList{
struct Node{
MyClass data;
std::unique_ptr<Node> next;
};
std::unique_ptr<Node> head;
// constructors etc. omitted.
};If we're going to access this from 2 threads, then we have a choice:
- We could wrap the whole object with a mutex, so only one thread is accessing the list at a time, or
- We could try and allow concurrent accesses.
For the sake of this article, we're going to assume we're allowing concurrent accesses.
Let's start simply: we want to traverse the list. Writing a traversal function is easy:
class MyList{
void traverse(std::function<void(MyClass)> f){
Node* p=head.get();
while(p){
f(p->data);
p=p->next;
}
};Assuming the list is immutable, this is fine, but immutable lists are no fun! We want to remove items from the front of our list. What changes do we need to make to support that?
Removing from the front of the list
If everything was single threaded, removing an element would be easy:
class MyList{
void pop_front(){
Node* p=head.get();
if(p){
head=std::move(p->next);
}
}
};If the list is not empty, the new head is the next pointer of the old head. However, we've got multiple threads accessing this list, so things aren't so straightforward.
Suppose we have a list of 3 elements.
A -> B -> C
If one thread is traversing the list, and another is removing the first element, there is a potential for a race.
- Thread X reads the
headpointer for the list and gets a pointer to A. - Thread Y removes A from the list and deletes it.
- Thread X tries to access the
datafor node A, but node A has been deleted, so we have a dangling pointer and undefined behaviour.
How can we fix it?
The first thing to change is to make all our std::unique_ptrs into
std::shared_ptrs, and have our traversal function take a std::shared_ptr
copy rather than using a raw pointer. That way, node A won't be deleted
immediately, since our traversing thread still holds a reference.
class MyList{
struct Node{
MyClass data;
std::shared_ptr<Node> next;
};
std::shared_ptr<Node> head;
void traverse(std::function<void(MyClass)> f){
std::shared_ptr<Node> p=head;
while(p){
f(p->data);
p=p->next;
}
}
void pop_front(){
std::shared_ptr<Node> p=head;
if(p){
head=std::move(p->next);
}
}
// constructors etc. omitted.
};Unfortunately that only fixes that race condition. There is a second race that is just as bad.
The second race condition
The second race condition is on head itself. In order to traverse the list,
thread X has to read head. In the mean time, thread Y is updating head. This
is the very definition of a data race, and is thus undefined behaviour.
We therefore need to do something to fix it.
We could use a mutex to protect head. This would be more fine-grained than a
whole-list mutex, since it would only be held for the brief time when the
pointer was being read or changed. However, we don't need to: we can use
std::experimental::atomic_shared_ptr instead.
The implementation is allowed to use a mutex internally with
atomic_shared_ptr, in which case we haven't gained anything with respect to
performance or concurrency, but we have gained by reducing the maintenance
load on our code. We don't have to have an explicit mutex data member, and we
don't have to remember to lock it and unlock it correctly around every access to
head. Instead, we can defer all that to the implementation with a single line
change:
class MyList{
std::experimental::atomic_shared_ptr<Node> head;
};Now, the read from head no longer races with a store to head: the
implementation of atomic_shared_ptr takes care of ensuring that the load gets
either the new value or the old one without problem, and ensuring that the
reference count is correctly updated.
Unfortunately, the code is still not bug free: what if 2 threads try and remove a node at the same time.
Race 3: double removal
As it stands, pop_front assumes it is the only modifying thread, which leaves
the door wide open for race conditions. If 2 threads call pop_front
concurrently, we can get the following scenario:
- Thread X loads
headand gets a pointer to node A. - Thread Y loads
headand gets a pointer to node A. - Thread X replaces
headwithA->next, which is node B. - Thread Y replaces
headwithA->next, which is node B.
So, two threads call pop_front, but only one node is removed. That's a bug.
The fix here is to use the ubiquitous compare_exchange_strong function, a staple
of any programmer who's ever written code that uses atomic variables.
class MyList{
void pop_front(){
std::shared_ptr<Node> p=head;
while(p &&
!head.compare_exchange_strong(p,p->next));
}
};If head has changed since we loaded it, then the call to
compare_exchange_strong will return false, and reload p for us. We then
loop again, checking that p is still non-null.
This will ensure that two calls to pop_front removes two nodes (if there are 2
nodes) without problems either with each other, or with a traversing thread.
Experienced lock-free programmers might well be thinking "what about the ABA problem?" right about now. Thankfully, we don't have to worry!
What no ABA problem?
That's right, pop_front does not suffer from the ABA problem. Even assuming
we've got a function that adds new values, we can never get a new value of
head the same as the old one. This is an additional benefit of using
std::shared_ptr: the old node is kept alive as long as one thread holds a
pointer. So, thread X reads head and gets a pointer to node A. This node is
now kept alive until thread X destroys or reassigns that pointer. That means
that no new node can be allocated with the same address, so if head is equal
to the value p then it really must be the same node, and not just some
imposter that happens to share the same address.
Lock-freedom
I mentioned earlier that implementations may use a mutex to provide the
synchronization in atomic_shared_ptr. They may also manage to make it
lock-free. This can be tested using the is_lock_free() member function common
to all the C++ atomic types.
The advantage of providing a lock-free atomic_shared_ptr should be obvious: by
avoiding the use of a mutex, there is greater scope for concurrency of the
atomic_shared_ptr operations. In particular, multiple concurrent reads can
proceed unhindered.
The downside will also be apparent to anyone with any experience with lock-free code: the code is more complex, and has more work to do, so may be slower in the uncontended cases. The other big downside of lock-free code (maintenance and correctness) is passed over to the implementor!
It is my belief that the scalability benefits outweight the complexity, which is
why Just::Thread v2.2 will ship with a lock-free
atomic_shared_ptr implementation.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: cplusplus, concurrency, multithreading
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
All the world's a stage... C++ Actors from Just::Thread Pro
Wednesday, 15 July 2015
Handling shared mutable state is probably the single hardest part of writing multithreaded code. There are lots of ways to address this problem; one of the common ones is the actors metaphor. Going back to Hoare's Communicating Sequential Processes, the idea is simple - you build your program out of a set of actors that send each other messages. Each actor runs normal sequential code, occasionally pausing to receive incoming messages from other actors. This means that you can analyse the behaviour of each actor independently; you only need to consider which messages might be received at each receive point. You could treat each actor as a state machine, with the messages triggering state transitions.
This is how Erlang processes work: each process is an actor, which runs independently from the other processes, except that they can send messages to each other. Just::thread Pro: Actors Edition adds library facilities to support this to C++. In the rest of this article I will describe how to write programs that take advantage of it. Though the details will differ, the approach can be used with other libraries that provide similar facilities, or with the actor support in other languages.
Simple Actors
Actors are embodied in the
jss::actor
class. You pass in a function or other callable object (such as a lambda
function) to the constructor, and this function is then run on a background
thread. This is exactly the same as for
std::thread,
except that the destructor waits for the actor thread to finish, rather than
calling std::terminate.
void simple_function(){
std::cout<<"simple actor\n";
}
int main(){
jss::actor actor1(simple_function);
jss::actor actor2([]{
std::cout<<"lambda actor\n";
});
}The waiting destructor is nice, but it's really a side issue — the main benefit of actors is the ability to communicate using messages rather than shared state.
Sending and receiving messages
To send a message to an actor you just call the
send()
member function on the actor object, passing in whatever message you wish to
send. send() is a function template, so you can send any type of message
— there are no special requirements on the message type, just that it is a
MoveConstructible type. You can also use the stream-insertion operator to send
a message, which allows easy chaining e.g.
actor1.send(42);
actor2.send(MyMessage("some data"));
actor2<<Message1()<<Message2();Sending a message to an actor just adds it to the actor's message queue. If the
actor never checks the message queue then the message does nothing. To check the
message queue, the actor function needs to call the
receive()
static member function of
jss::actor. This
is a static member function so that it always has access to the running actor,
anywhere in the code — if it were a non-static member function then you
would need to ensure that the appropriate object was passed around, which would
complicate interfaces, and open up the possibility of the wrong object being
passed around, and lifetime management issues.
The call to jss::actor::receive() will then block the actor's thread until a
message that it can handle has been received. By default, the only message type
that can be handled is jss::stop_actor. If a message of this type is sent to
an actor then the receive() function will throw a jss::stop_actor
exception. Uncaught, this exception will stop the actor running. In the
following example, the only output will be "Actor running", since the actor will
block at the receive() call until the stop message is sent, and when the message
arrives, receive() will throw.
void stoppable_actor(){
std::cout<<"Actor running"<<std::endl;
jss::actor::receive();
std::cout<<"This line is never run"<<std::endl;
}
int main(){
jss::actor a1(stoppable_actor);
std::this_thread::sleep_for(std::chrono::seconds(1));
a1.send(jss::stop_actor());
}Sending a "stop" message is common-enough that there's a special member function
for that too:
stop(). "a1.stop()"
is thus equivalent to "a1.send(jss::stop_actor())".
Handling a message of another type requires that you tell the receive() call
what types of message you can handle, which is done by chaining one or more
calls to the
match()
function template. You must specify the type of the message to handle, and then
provide a function to call if the message is received. Any messages other than
jss::stop_actor not specified in a match() call will be removed from the queue,
but otherwise ignored. In the following example, only messages of type "int" and
"std::string" are accepted; the output is thus:
Waiting
42
Waiting
Hello
Waiting
DoneHere's the code:
void simple_receiver(){
while(true){
std::cout<<"Waiting"<<std::endl;
jss::actor::receive()
.match<int>([](int i){std::cout<<i<<std::endl;})
.match<std::string>([](std::string const&s){std::cout<<s<<std::endl;});
}
}
int main(){
{
jss::actor a(simple_receiver);
a.send(true);
a.send(42);
a.send(std::string("Hello"));
a.send(3.141);
a.send(jss::stop_actor());
} // wait for actor to finish
std::cout<<"Done"<<std::endl;
}It is important to note that the receive() call will block until it receives
one of the messages you have told it to handle, or a jss::stop_actor message,
and unexpected messages will be removed from the queue and discarded. This means
the actors don't accumulate a backlog of messages they haven't yet said they can
handle, and you don't have to worry about out-of-order messages messing up a
receive() call.
These simple examples have just had main() sending messages to the actors. For
a true actor-based system we need them to be able to send messages to each
other, and reply to messages. Let's take a look at how we can do that.
Referencing one actor from another
Suppose we want to write a simple time service actor, that sends the current
time back to any other actor that asks it for the time. At first thought it
looks rather simple: write a simple loop that handles a "time request" message,
gets the time, and sends a response. It won't be that much different from our
simple_receiver() function above:
struct time_request{};
void time_server(){
while(true){
jss::actor::receive()
.match<time_request>([](time_request r){
auto now=std::chrono::system_clock::now();
????.send(now);
});
}
}The problem is, we don't know which actor to send the response to — the
whole point of this time server is that it will respond to a message from any
other actor. The solution is to pass the sender as part of the message. We could
just pass a pointer or reference to the jss::actor instance, but that requires
that the actor knows the location of its own controlling object, which makes it
more complicated — none of the examples we've had so far could know that,
since the controlling object is a local variable declared in a separate
function. What is needed instead is a simple means of identifying an actor,
which the actor code can query — an actor reference. The type of an actor
reference is
jss::actor_ref,
which is implicitly constructible from a jss::actor. An actor can also obtain
a reference to itself by calling
jss::actor::self(). jss::actor_ref
has a
send()
member function and stream insertion operator for sending messages, just like
jss::actor. So, we can put the sender of our time_request message in the message
itself as a jss::actor_ref data member, and use that when sending the response.
struct time_request{
jss::actor_ref sender;
};
void time_server(){
while(true){
jss::actor::receive()
.match<time_request>([](time_request r){
auto now=std::chrono::system_clock::now();
r.sender<<now;
});
}
}
void query(jss::actor_ref server){
server<<time_request{jss::actor::self()};
jss::actor::receive()
.match<std::chrono::system_clock::time_point>(
[](std::chrono::system_clock::time_point){
std::cout<<"time received"<<std::endl;
});
}Dangling references
If you use jss::actor_ref then you have to be prepared for the case that the
referenced actor might have stopped executing by the time you send the
message. In this case, any attempts to send a message through the
jss::actor_ref instance will throw an exception of type
[jss::no_actor]http://www.stdthread.co.uk/prodoc/headers/actor/no_actor.html. To
be robust, our time server really ought to handle that too — if an
unhandled exception of any type other than jss::stop_actor escapes the actor
function then the library will call std::terminate. We should therefore wrap the
attempt to send the message in a try-catch block.
void time_server(){
while(true){
jss::actor::receive()
.match<time_request>([](time_request r){
auto now=std::chrono::system_clock::now();
try{
r.sender<<now;
} catch(jss::no_actor&){}
});
}
}We can now set up a pair of actors that play ping-pong:
struct pingpong{
jss::actor_ref sender;
};
void pingpong_player(std::string message){
while(true){
try{
jss::actor::receive()
.match<pingpong>([&](pingpong msg){
std::cout<<message<<std::endl;
std::this_thread::sleep_for(std::chrono::milliseconds(50));
msg.sender<<pingpong{jss::actor::self()};
});
}
catch(jss::no_actor&){
std::cout<<"Partner quit"<<std::endl;
break;
}
}
}
int main(){
jss::actor ping(pingpong_player,"ping");
jss::actor pong(pingpong_player,"pong");
ping<<pingpong{pong};
std::this_thread::sleep_for(std::chrono::seconds(1));
ping.stop();
pong.stop();
}This will give output along the lines of the following:
ping
pong
ping
pong
ping
pong
ping
pong
ping
pong
ping
pong
ping
pong
ping
pong
ping
pong
ping
pong
Partner quitThe sleep in the player's message handler is to slow everything down — if
you take it out then messages will go back and forth as fast as the system can
handle, and you'll get thousands of lines of output. However, even at full speed
the pings and pongs will be interleaved, because sending a message synchronizes
with the receive() call that receives it.
That's essentially all there is to it — the rest is just application design. As an example of how it can all be put together, let's look at an implementation of the classic sleeping barber problem.
The Lazy Barber
For those that haven't met it before, the problem goes like this: Mr Todd runs a barber shop, but he's very lazy. If there are no customers in the shop then he likes to go to sleep. When a customer comes in they have to wake him up if he's asleep, take a seat if there is one, or come back later if there are no free seats. When Mr Todd has cut someone's hair, he must move on to the next customer if there is one, otherwise he can go back to sleep.
The barber actor
Let's start with the barber. He sleeps in his chair until a customer comes in, then wakes up and cuts the customer's hair. When he's done, if there is a waiting customer he cuts that customer's hair. If there are no customers, he goes back to sleep, and finally at closing time he goes home. This is shown as a state machine in figure 1.
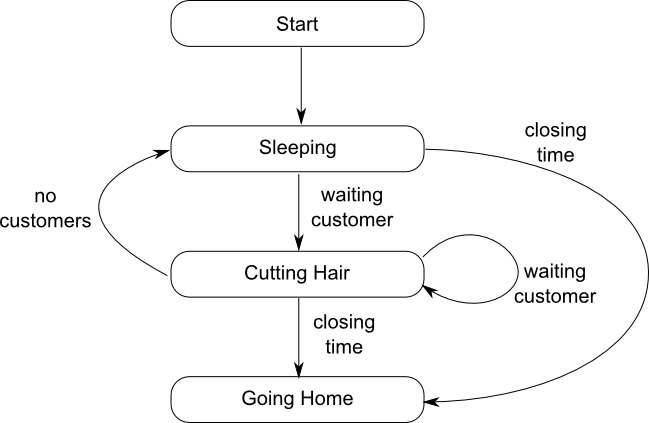
This translates into code as shown in listing 1.The wait
loops for "sleeping" and "cutting hair" have been combined, since almost the
same set of messages is being handled in each case — the only difference
is that the "cutting hair" state also has the option of "no customers", which
cannot be received in the "sleeping" state, and would be a no-op if it was. This
allows the action associated with the "cutting hair" state to be entirely
handled in the lambda associated with the customer_waiting message; splitting
the wait loops would require that the code was extracted out to a separate
function, which would make it harder to keep count of the haircuts. Of course,
if you don't have a compiler with lambda support then you'll need to do that
anyway. The logger is a global actor that receives std::strings as messages
and writes them to std::cout. This avoids any synchronization issues with
multiple threads trying to write out at once, but it does mean that you have to
pre-format the strings, such as when logging the number of haircuts done in the
day. The code for this is shown in listing 2.
The customer actor
Let's look at things from the other side: the customer. The customer goes to town, and does some shopping. Each customer periodically goes into the barber shop to try and get a hair cut. If they manage, or the shop is closed, then they go home, otherwise they do some more shopping and go back to the barber shop later. This is shown in the state machine in figure 2.
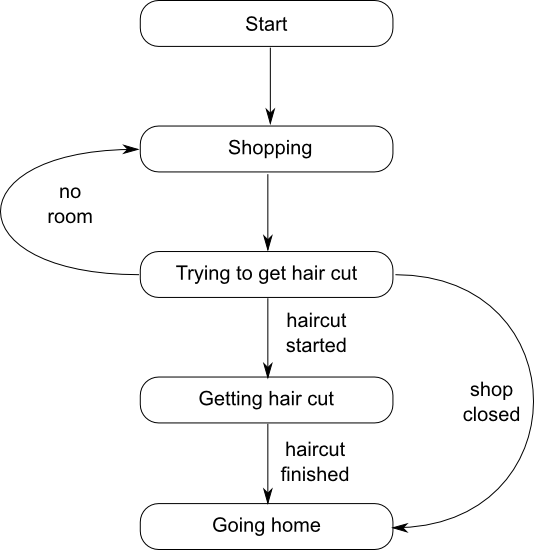
This translates into the code in listing 3. Note that the customer
interacts with a "shop" actor that I haven't mentioned yet. It is often
convenient to have an actor that represents shared state, since this allows
access to the shared state from other actors to be serialized without needing an
explicit mutex. In this case, the shop holds the number of waiting customers,
which must be shared with any customers that come in, so they know whether there
is a free chair or not. Rather than have the barber have to deal with messages
from new customers while he is cutting hair, the shop acts as an
intermediary. The customer also has to handle the case that the shop has already
closed, so the shop reference might refer to an actor that has finished
executing, and thus get a jss::no_actor exception when trying to send
messages.
The message handlers for the shop are short, and just send out further messages to the barber or the customer, which is ideal for a simple state-manager — you don't want other actors waiting to perform simple state checks because the state manager is performing a lengthy operation; this is why we separated the shop from the barber. The shop has 2 states: open, where new customers are accepted provided there are fewer than the remaining spaces, and closed, where new customers are turned away, and the shop is just waiting for the last customer to leave. If a customer comes in, and there is a free chair then a message is sent to the barber that there is a customer waiting; if there is no space then a message is sent back to the customer to say so. When it's closing time then we switch to the "closing" state — in the code we exit the first while loop and enter the second. This is all shown in listing 4.
The messages are shown in listing 5, and the main() function that drives it all is in listing 6.
Exit stage left
There are of course other ways of writing code to deal with any particular scenario, even if you stick to using actors. This article has shown some of the issues that you need to think about when using an actor-based approach, as well as demonstrating how it all fits together with the Just::Thread Pro actors library. Though the details will be different, the larger issues will be common to any implementation of the actor model.
Get the code
If you want to download the code for a better look, or to try it out, you can download it here.
Get your copy of Just:::Thread Pro
If you like the idea of working with actors in your code, now is the ideal time to get Just::Thread Pro. Get your copy now.
This blog post is based on an article that was printed in the July 2013 issue of CVu, the Journal of the ACCU.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: cplusplus, actors, concurrency, multithreading
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
New Concurrency Features in C++14
Wednesday, 08 July 2015
It might have been out for 7 months already, but the C++14 standard is still pretty fresh. The changes include a couple of enhancements to the thread library, so I thought it was about time I wrote about them here.
Shared locking
The biggest of the changes is the addition of
std::shared_timed_mutex. This
is a multiple-reader, single-writer mutex. This means that in addition to the
single-ownership mode supported by the other standard mutexes, you can also lock
it in shared ownership mode, in which case multiple threads may hold a shared
ownership lock at the same time.
This is commonly used for data structures that are read frequently but modified only rarely. When the data structure is stable, all threads that want to read the data structure are free to do so concurrently, but when the data structure is being modified then only the thread doing the modification is permitted to access the data structure.
The timed part of the name is analagous to
std::timed_mutex
and
std::recursive_timed_mutex:
timeouts can be specified for any attempt to acquire a lock, whether a
shared-ownership lock or a single-ownership lock. There is a proposal to add a
plain std::shared_mutex to the next standard, since this can have lower
overhead on some platforms.
To manage the new shared ownership mode there are a new set of member functions:
lock_shared(),
try_lock_shared(),
unlock_shared(),
try_lock_shared_for()
and
try_lock_shared_until(). Obtaining
and releasing the single-ownership lock is performed with the same set of
operations as for std::timed_mutex.
However, it is generally considered bad practise to use these functions directly
in C++, since that leaves the possibility of dangling locks if a code path
doesn't release the lock correctly. It is better to use
std::lock_guard
and
std::unique_lock
to perform lock management in the single-ownership case, and the
shared-ownership case is no different: the C++14 standard also provides a new
std::shared_lock
class template for managing shared ownership locks. It works just the same as
std::unique_lock; for common use cases it acquires the lock in the
constructor, and releases it in the destructor, but there are member functions
to allow alternative access patterns.
Typical uses will thus look like the following:
std::shared_timed_mutex m;
my_data_structure data;
void reader(){
std::shared_lock<std::shared_timed_mutex> lk(m);
do_something_with(data);
}
void writer(){
std::lock_guard<std::shared_timed_mutex> lk(m);
update(data);
}Performance warning
The implementation of a mutex that supports shared ownership is inherently more
complex than a mutex that only supports exclusive ownership, and all the
shared-ownership locks still need to modify the mutex internals. This means that
the mutex itself can become a point of contention, and sap performance. Whether
using a std::shared_timed_mutex instead of a std::mutex provides better or
worse performance overall is therefore strongly dependent on the work load and
access patterns.
As ever, I therefore strongly recommend profiling your application with
std::mutex and std::shared_timed_mutex in order to ascertain which performs
best for your use case.
std::chrono enhancements
The other concurrency enhancements in the C++14 standard are all in the
<chrono> header. Though this isn't strictly about concurrency, it is used for
all the timing-related functions in the concurrency library, and is therefore
important for any threaded code that has timeouts.
constexpr all round
The first change is that the library has been given a hefty dose of constexpr
goodness. Instances of std::chrono::duration and std::chrono::time_point now
have constexpr constructors and simple arithmetic operations are also
constexpr. This means you can now create durations and time points which are
compile-time constants. It also means they are literal types, which is
important for the other enhancement to <chrono>: user-defined literals for
durations.
User-defined literals
C++11 introduced the idea of user-defined literals, so you could provide a
suffix to numeric and string literals in your code to construct a user-defined
type of object, much as 3.2f creates a float rather than the default
double, however there were no new types of literals provided by the standard
library.
C++14 changes that. We now have user-defined literals for
std::chrono::duration, so you can write 30s instead of
std::chrono::seconds(30). To get this user-defined literal goodness you need
to explicitly enable it in your code with a using directive — you might have
other code that wants to use these suffixes for a different set of types, so the
standard let's you choose.
That using directive is:
using namespace std::literals::chrono_literals;The supported suffixes are:
h→std::chrono::hoursmin→std::chrono::minutess→std::chrono::secondsms→std::chrono::millisecondsus→std::chrono::microsecondsns→std::chrono::nanoseconds
You can therefore wait for a shared ownership lock with a 50 millisecond timeout like this:
void foo(){
using namespace std::literals::chrono_literals;
std::shared_lock<std::shared_timed_mutex> lk(m,50ms);
if(lk.owns_lock()){
do_something_with_lock_held();
}
else {
do_something_without_lock_held();
}
}Just::Thread support
As you might expect, Just::Thread provides an
implementation of all of this. std::shared_timed_mutex is available on all
supported platforms, but the constexpr and user-defined literal enhancements
are only available for those compilers that support the new language features:
gcc 4.6 or later for constexpr and gcc 4.7 or later for user-defined
literals, with the -std=c++11 or std=c++14 switch enabled in either case.
Get your copy of Just::Thread while
our 10th anniversary sale is on for a 50% discount.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: cplusplus, concurrency
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Locks, Mutexes, and Semaphores: Types of Synchronization Objects
Tuesday, 21 October 2014
I recently got an email asking about locks and different types of synchronization objects, so I'm posting this entry in case it is of use to others.
Locks
A lock is an abstract concept. The basic premise is that a lock protects access to some kind of shared resource. If you own a lock then you can access the protected shared resource. If you do not own the lock then you cannot access the shared resource.
To own a lock, you first need some kind of lockable object. You then acquire the lock from that object. The precise terminology may vary. For example, if you have a lockable object XYZ you may:
- acquire the lock on XYZ,
- take the lock on XYZ,
- lock XYZ,
- take ownership of XYZ,
- or some similar term specific to the type of XYZ
The concept of a lock also implies some kind of exclusion: sometimes you might be unable to take ownership of a lock, and the operation to do so will either fail, or block. In the former case, the operation will return some error code or exception to indicate that the attempt to take ownership failed. In the latter case, the operation will not return until it has taken ownership, which typically requires that another thread in the system does something to permit that to happen.
The most common form of exclusion is a simple numerical count: the lockable object has a maximum number of owners. If that number has been reached, then any further attempt to acquire a lock on it will be unable to succeed. This therefore requires that we have some mechanism of relinquishing ownership when we are done. This is commonly called unlocking, but again the terminology may vary. For example, you may:
- release the lock on XYZ,
- drop the lock on XYZ,
- unlock XYZ,
- relinquish ownership of XYZ,
- or some similar term specific to the type of XYZ
When you relinquish ownership in the appropriate fashion then a blocked operation that is trying to acquire the lock may not proceed, if the required conditions have been met.
For example if a lockable object only allows 3 owners then a 4th attempt to acquire the lock will block. When one of the first 3 owners releases the lock then that 4th attempt to acquire the lock will succeed.
Ownership
What it means to "own" a lock depends on the precise type of the lockable object. For some lockable objects there is a very tight definition of ownership: this specific thread owns the lock, through the use of that specific object, within this particular scope.
In other cases, the definition is more fluid, and the ownership of the lock is more conceptual. In these cases, ownership can be relinquished by a different thread or object than the thread or object that acquired the lock.
Mutexes
Mutex is short for MUTual EXclusion. Unless the word is qualified with additional terms such as shared mutex, recursive mutex or read/write mutex then it refers to a type of lockable object that can be owned by exactly one thread at a time. Only the thread that acquired the lock can release the lock on a mutex. When the mutex is locked, any attempt to acquire the lock will fail or block, even if that attempt is done by the same thread.
Recursive Mutexes
A recursive mutex is similar to a plain mutex, but one thread may own multiple locks on it at the same time. If a lock on a recursive mutex has been acquired by thread A, then thread A can acquire further locks on the recursive mutex without releasing the locks already held. However, thread B cannot acquire any locks on the recursive mutex until all the locks held by thread A have been released.
In most cases, a recursive mutex is undesirable, since the it makes it harder to reason correctly about the code. With a plain mutex, if you ensure that the invariants on the protected resource are valid before you release ownership then you know that when you acquire ownership those invariants will be valid.
With a recursive mutex this is not the case, since being able to acquire the lock does not mean that the lock was not already held, by the current thread, and therefore does not imply that the invariants are valid.
Reader/Writer Mutexes
Sometimes called shared mutexes, multiple-reader/single-writer mutexes or just read/write mutexes, these offer two distinct types of ownership:
- shared ownership, also called read ownership, or a read lock, and
- exclusive ownership, also called write ownership, or a write lock.
Exclusive ownership works just like ownership of a plain mutex: only one thread may hold an exclusive lock on the mutex, only that thread can release the lock. No other thread may hold any type of lock on the mutex whilst that thread holds its lock.
Shared ownership is more lax. Any number of threads may take shared ownership of a mutex at the same time. No thread may take an exclusive lock on the mutex while any thread holds a shared lock.
These mutexes are typically used for protecting shared data that is seldom updated, but cannot be safely updated if any thread is reading it. The reading threads thus take shared ownership while they are reading the data. When the data needs to be modified, the modifying thread first takes exclusive ownership of the mutex, thus ensuring that no other thread is reading it, then releases the exclusive lock after the modification has been done.
Spinlocks
A spinlock is a special type of mutex that does not use OS synchronization functions when a lock operation has to wait. Instead, it just keeps trying to update the mutex data structure to take the lock in a loop.
If the lock is not held very often, and/or is only held for very short periods, then this can be more efficient than calling heavyweight thread synchronization functions. However, if the processor has to loop too many times then it is just wasting time doing nothing, and the system would do better if the OS scheduled another thread with active work to do instead of the thread failing to acquire the spinlock.
Semaphores
A semaphore is a very relaxed type of lockable object. A given semaphore has a predefined maximum count, and a current count. You take ownership of a semaphore with a wait operation, also referred to as decrementing the semaphore, or even just abstractly called P. You release ownership with a signal operation, also referred to as incrementing the semaphore, a post operation, or abstractly called V. The single-letter operation names are from Dijkstra's original paper on semaphores.
Every time you wait on a semaphore, you decrease the current count. If the count was greater than zero then the decrement just happens, and the wait call returns. If the count was already zero then it cannot be decremented, so the wait call will block until another thread increases the count by signalling the semaphore.
Every time you signal a semaphore, you increase the current count. If the count was zero before you called signal, and there was a thread blocked in wait then that thread will be woken. If multiple threads were waiting, only one will be woken. If the count was already at its maximum value then the signal is typically ignored, although some semaphores may report an error.
Whereas mutex ownership is tied very tightly to a thread, and only the thread that acquired the lock on a mutex can release it, semaphore ownership is far more relaxed and ephemeral. Any thread can signal a semaphore, at any time, whether or not that thread has previously waited for the semaphore.
An analogy
A semaphore is like a public lending library with no late fees. They might have 5 copies of C++ Concurrency in Action available to borrow. The first five people that come to the library looking for a copy will get one, but the sixth person will either have to wait, or go away and come back later.
The library doesn't care who returns the books, since there are no late fees, but when they do get a copy returned, then it will be given to one of the people waiting for it. If no-one is waiting, the book will go on the shelf until someone does want a copy.
Binary semaphores and Mutexes
A binary semaphore is a semaphore with a maximum count of 1. You can use a binary semaphore as a mutex by requiring that a thread only signals the semaphore (to unlock the mutex) if it was the thread that last successfully waited on it (when it locked the mutex). However, this is only a convention; the semaphore itself doesn't care, and won't complain if the "wrong" thread signals the semaphore.
Critical Sections
In synchronization terms, a critical section is that block of code during which a lock is owned. It starts at the point that the lock is acquired, and ends at the point that the lock is released.
Windows CRITICAL_SECTIONs
Windows programmers may well be familiar with CRITICAL_SECTION objects. A
CRITICAL_SECTION is a specific type of mutex, not a use of the general term
critical section.
Mutexes in C++
The C++14 standard has five mutex types:
The variants with "timed" in the name are the same as those without, except that the lock operations can have time-outs specified, to limit the maximum wait time. If no time-out is specified (or possible) then the lock operations will block until the lock can be acquired — potentially forever if the thread that holds the lock never releases it.
std::mutex and std::timed_mutex are just plain single-owner mutexes.
std::recursive_mutex and std::recursive_timed_mutex are recursive mutexes,
so multiple locks may be held by a single thread.
std::shared_timed_mutex is a read/write mutex.
C++ lock objects
To go with the various mutex types, the C++ Standard defines a triplet of class templates for objects that hold a lock. These are:
For basic operations, they all acquire the lock in the constructor, and release it in the destructor, though they can be used in more complex ways if desired.
std::lock_guard<> is the simplest type, and just holds a lock across a
critical section in a single block:
std::mutex m;
void f(){
std::lock_guard<std::mutex> guard(m);
// do stuff
}std::unique_lock<> is similar, except it can be returned from a function
without releasing the lock, and can have the lock released before the
destructor:
std::mutex m;
std::unique_lock<std::mutex> f(){
std::unique_lock<std::mutex> guard(m);
// do stuff
return std::move(guard);
}
void g(){
std::unique_lock<std::mutex> guard(f());
// do more stuff
guard.unlock();
}See my previous
blog post
for more about std::unique_lock<> and std::lock_guard<>.
std::shared_lock<> is almost identical to std::unique_lock<> except that it
acquires a shared lock on the mutex. If you are using a
std::shared_timed_mutex then you can use
std::lock_guard<std::shared_timed_mutex> or
std::unique_lock<std::shared_timed_mutex> for the exclusive lock, and
std::shared_lock<std::shared_timed_mutex> for the shared lock.
std::shared_timed_mutex m;
void reader(){
std::shared_lock<std::shared_timed_mutex> guard(m);
// do read-only stuff
}
void writer(){
std::lock_guard<std::shared_timed_mutex> guard(m);
// update shared data
}Semaphores in C++
The C++ standard does not define a semaphore type. You can write your own with an atomic counter, a mutex and a condition variable if you need, but most uses of semaphores are better replaced with mutexes and/or condition variables anyway.
Unfortunately, for those cases where semaphores really are what you want, using
a mutex and a condition variable adds overhead, and there is nothing in the C++
standard to help. Olivier Giroux and Carter Edwards' proposal for a
std::synchronic class template
(N4195)
might allow for an efficient implementation of a semaphore, but this is still
just a proposal.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: locks, mutexes, semaphores, multithreading, synchronization
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
C++ Concurrency in Action and Just::Thread Discounts
Wednesday, 25 April 2012

My book C++ Concurrency in Action was finally published on 29th February 2012, after 4 years of work. It's hard to believe that I can actually hold a copy in my hand; it's just been files on my computer for so long.
My book is a tutorial and reference to the thread library from the new C++11 standard. It also provides various guidelines for writing and testing multithreaded code, as well as sample implementations of thread-safe data structures and parallel algorithms
If you haven't already got a copy, you can order one direct from Manning, or from amazon.com, or amazon.co.uk. Alternatively, copies should be available at the ACCU 2012 conference in Oxford this week.
Discount on Just::Thread
If you have purchased the book then send a copy of your receipt or other proof of purchase to info@justsoftwaresolutions.co.uk for a 50% discount on a single user license of Just::Thread, our implementation of the C++11 thread library described in the book for Microsoft Visual Studio on Windows, and g++ on Windows, Linux and MacOSX.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: c++, concurrency, book, multithreading
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Thread-Safe Copy and Move Constructors
Wednesday, 17 August 2011
This is a guest post by Michael Spertus. Michael is a Distinguished Engineer at Symantec. He is also a C++ Standards Committee member and teaches the graduate C++ sequence at the University of Chicago. He can be contacted at mike_spertus@symantec.com.
This guest column discusses writing thread-safe constructors. As we will see, this is more difficult than it seems. Fortunately, we will also see that C++11 offers a very pretty solution to this problem that nicely illustrates the synergy of the new features introduced in C++11.
The problem
If you have a class that supports locking of objects to serialize access to a given object, you probably want the class' copy constructor and move constructor (if it has one) to lock the source object to get a consistent snapshot of the source object so the destination object isn't messed up if the source changes in the middle of the copy or move.
This isn't nearly as easy as it sounds. In the following class, a
mutex is used to try to enforce the invariant that i_squared
should always be the square of i.
class A {
public: A(_i = 0) { set(_i); }
set(int _i) {
std::lock_guard<std::mutex> lock(mtx);
i = _i;
i_squared = i*i;
}
...
private:
std::mutex mtx;
int i;
int i_squared;
};
Unfortunately, the default copy constructor doesn't acquire the
mutex, so in code like the following, f
can copy a "half set" version of a
if another thread modifies a
at the same time.
void f(A &a)
{
A a2 = a;
...
}
First attempt
A naive attempt is to acquire the lock in the constructor body just like in a thread-safe method.
class A {
public:
A(const A &a) : i(a.i), i_squared(a.i_squared) {
std::lock_guard<std::mutex> lock(a.mtx); // Too late!
}
...
};
Unfortunately, this fares no better
as i and i_squared are
copied before we acquire the lock.
Second attempt
One approach would be to simply not lock in the copy constructor at all and just manually lock objects you want to copy:
void f(A &a)
{
std::lock_guard<std::mutex>
lock(a.mtx);
A a2 = a;
...
}
This approach deserves careful consideration. For classes which
are not usually shared between threads or which need locking granularity
at a different level than their internal operations, managing locks
within the class can be an antipattern. This concern was a primary reason
why C++11 does not have an equivalent to the SynchronizedCollection
wrapper found in Java and C#. For example, synchronized
collections make it easy to inadvertently loop through a collection believing
your code is thread-safe even though the collection could change between
individual operations on the collection during the loop. Of course, if
we decide not to have A's copy constructor lock, then A::set()
should not lock either.
Still, it remains a very common and useful pattern for classes designed for shared
use to have all their internal operations acquire the
lock (i.e.,
monitors/synchronized classes).
If A is a synchronized class that locks its methods internally, it would
be very confusing and prone to intermittent errors to still have to manually acquire
the
lock whenever an object is copied or moved. Also, generic
code, which doesn't know about A::mtx is unlikely to work
properly.
Third attempt
One thing we can do is dispense with member initialization lists in constructors altogether
class A {
public:
A(const A &a) {
std::lock_guard<std::mutex> lock(a.mtx);
i = a.i;
i_squared = a.i_squared;
}
...
};
This solution is awkward at best if any bases or members don't have default constructors, have reference type, or are const. It also seems unfair to have to pay an efficiency penalty (for constructing and assigning separately) just because there is no place to put the lock. In practice, I also suspect intermittent errors will creep into large code bases as programmers carelessly add a base or member initializer to the constructor. Finally, it just isn't very satisfying to have to just discard core parts of constructor syntax just because your class is synchronized.
Fourth attempt
Anthony Williams has suggested implementing serialized classes using a wrapper class like:
struct PrivateBaseForA
{
int i;
int i_squared;
};
class A: private PrivateBaseForA
{
mutable std::mutex mtx;
public:
A(int _i = 0) { set(_i); }
void set(int _i) {
std::lock_guard<std::mutex> lock(mtx);
i = _i;
i_squared = _i*_i;
}
A(const A& other):
PrivateBaseForA((std::lock_guard<std::mutex>(other.mtx),other))
{}
};
Anthony makes slick use of double-parens to use the comma operator. If you
wanted to avoid this, you could have PrivateBaseForA's constructor take a lock.
Again, this is not yet a very satisfying solution because writing a wrapper class for every synchronized class just to get a properly locked copy constructor is clumsy and intrusive.
Finally, the C++11 approach
Fortunately, C++11 offers a nice solution that really illustrates how beautifully and powerfully the features of C++11 work together. C++11 supports forwarding one constructor to another, which gives us an opportunity to grab the mutex before any copying or moving takes place:
class A {
private:
A(const A &a, const std::lock_guard<std::mutex> &)
: i(a.i), i_squared(a.i_squared) {}
public:
A(const A &a) : A(a, std::lock_guard<std::mutex>(a.mtx)) {}
...
};
This solution locks the entire constructor, protects against races resulting from forgetting the manual lock, works with generic code, and doesn't require the creation of artificial wrapper classes.
While I think this is clearly the preferred solution, it is not perfect. To begin with, it is more obscure and guru-like than I would wish for such a common situation. Secondly, constructor forwarding is not yet implemented by any major C++ compiler (although the recently approved standard should change that soon). Finally, we lose the benefit of compiler generated copy constructors. If we added an i_cubed field to A that also needed to be kept consistent with i, we might forget to update the private constructor. Perhaps this will be a further opportunity for the next C++ standard (C++1y?). In the meantime, C++11 provides a powerful new solution to the everyday problem of writing thread-safe copy and move constructors.
One final note is to mention that although this article focused on copy constructors, everything applies equally to move constructors. Indeed, any constructor that needs to acquire any lock whatsoever (e.g., a database lock) for its entire duration can apply these techniques.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: multithreading, copying
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Simplify Code by Encapsulating Locks
Wednesday, 15 June 2011
Over on the Future Chips blog, Aater Suleman argues
that while(1)
can make parallel code better. Whilst I agree that the code
using while(1) is simpler than the original in terms of
analysing the lock patterns, it achieves this by testing the logical
condition inside the while and
using break. This is additional, unnecessary,
complexity.
What is wanted instead is a way of encapsulating the locking, so that the loop logic is simple, and yet the lock logic is also clear.
Here is the original code from the blog post:
lock_acquire(lock);
while(check_condition()){
lock_release(lock);
//do any actual work in the iteration - Thanks to Caleb for this comment
lock_acquire(lock);
}
lock_release(lock);
The implication here is that check_condition() must be
called with the lock held, but the lock need not be held for the
actual iteration work. The code thus acquires and releases the mutex
in two places, which is unnecessary duplication, and a potential
source of errors — if the loop exits early then the lock may
be released twice, for example.
Rather than moving the condition check into the loop to avoid this duplication, a better solution is to move the lock acquisition and release into the condition check:
bool atomic_check_condition()
{
lock_acquire(lock);
bool result=check_condition();
lock_release(lock);
return result;
}
while(atomic_check_condition()){
//do any actual work in the iteration - Thanks to Caleb for this comment
}
This gives us the best of both worlds: the lock is now held only
across the check_condition() call, but the logic of
the while loop is still clear.
If you're programming in C++, then the C++0x library allows us to
make atomic_check_condition() even simpler by
using lock_guard as in the code below, but extracting
the function is always an improvement.
bool atomic_check_condition()
{
std::lock_guard<mutex_type> guard(lock);
return check_condition();
}
Posted by Anthony Williams
[/ threading /] permanent link
Tags: multithreading, concurrency, locks
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Definitions of Non-blocking, Lock-free and Wait-free
Tuesday, 07 September 2010
There have repeatedly been posts on comp.programming.threads asking for a definition of these terms. To write good multithreaded code you really need to understand what these mean, and how they affect the behaviour and performance of algorithms with these properties. I thought it would be therefore be useful to provide some definitions.
Definition of Blocking
A function is said to be blocking if it calls an operating system function that waits for an event to occur or a time period to elapse. Whilst a blocking call is waiting the operating system can often remove that thread from the scheduler, so it takes no CPU time until the event has occurred or the time has elapsed. Once the event has occurred then the thread is placed back in the scheduler and can run when allocated a time slice. A thread that is running a blocking call is said to be blocked.
Mutex lock functions such
as std::mutex::lock(),
and EnterCriticalSection()
are blocking, as are wait functions such
as std::future::wait()
and std::condition_variable::wait(). However,
blocking functions are not limited to synchronization facilities:
the most common blocking functions are I/O facilities such
as fread() or WriteFile(). Timing
facilities such
as Sleep(),
or std::this_thread::sleep_until()
are also often blocking if the delay period is long enough.
Definition of Non-blocking
Non-blocking functions are just those that aren't blocking. Non-blocking data structures are those on which all operations are non-blocking. All lock-free data structures are inherently non-blocking.
Spin-locks are an example of non-blocking synchronization: if one thread has a lock then waiting threads are not suspended, but must instead loop until the thread that holds the lock has released it. Spin locks and other algorithms with busy-wait loops are not lock-free, because if one thread (the one holding the lock) is suspended then no thread can make progress.
Defintion of lock-free
A lock-free data structure is one that doesn't use any
mutex locks. The implication is that multiple threads can access the
data structure concurrently without race conditions or data
corruption, even though there are no locks — people would give
you funny looks if you suggested that std::list was a
lock-free data structure, even though it is unlikely that there are
any locks used in the implementation.
Just because more than one thread can safely access a lock-free data structure concurrently doesn't mean that there are no restrictions on such accesses. For example, a lock-free queue might allow one thread to add values to the back whilst another removes them from the front, whereas multiple threads adding new values concurrently would potentially corrupt the data structure. The data structure description will identify which combinations of operations can safely be called concurrently.
For a data structure to qualify as lock-free, if any thread performing an operation on the data structure is suspended at any point during that operation then the other threads accessing the data structure must still be able to complete their tasks. This is the fundamental restriction which distinguishes it from non-blocking data structures that use spin-locks or other busy-wait mechanisms.
Just because a data structure is lock-free it doesn't mean that threads don't have to wait for each other. If an operation takes more than one step then a thread may be pre-empted by the OS part-way through an operation. When it resumes the state may have changed, and the thread may have to restart the operation.
In some cases, a the partially-completed operation would prevent other threads performing their desired operations on the data structure until the operation is complete. In order for the algorithm to be lock-free, these threads must then either abort or complete the partially-completed operation of the suspended thread. When the suspended thread is woken by the scheduler it can then either retry or accept the completion of its operation as appropriate. In lock-free algorithms, a thread may find that it has to retry its operation an unbounded number of times when there is high contention.
If you use a lock-free data structure where multiple threads modify the same pieces of data and thus cause each other to retry then high rates of access from multiple threads can seriously cripple the performance, as the threads hinder each other's progress. This is why wait-free data structures are so important: they don't suffer from the same set-backs.
Definition of wait-free
A wait-free data structure is a lock-free data structure with the additional property that every thread accessing the data structure can make complete its operation within a bounded number of steps, regardless of the behaviour of other threads. Algorithms that can involve an unbounded number of retries due to clashes with other threads are thus not wait-free.
This property means that high-priority threads accessing the data structure never have to wait for low-priority threads to complete their operations on the data structure, and every thread will always be able to make progress when it is scheduled to run by the OS. For real-time or semi-real-time systems this can be an essential property, as the indefinite wait-periods of blocking or non-wait-free lock-free data structures do not allow their use within time-limited operations.
The downside of wait-free data structures is that they are more complex than their non-wait-free counterparts. This imposes an overhead on each operation, potentially making the average time taken to perform an operation considerably longer than the same operation on an equivalent non-wait-free data structure.
Choices
When choosing a data structure for a given task you need to think about the costs and benefits of each of the options.
A lock-based data structure is probably the easiest to use, reason about and write, but has the potential for limited concurrency. They may also be the fastest in low-load scenarios.
A lock-free (but not wait-free) data structure has the potential to allow more concurrent accesses, but with the possibility of busy-waits under high loads. Lock-free data structures are considerably harder to write, and the additional concurrency can make reasoning about the program behaviour harder. They may be faster than lock-based data structures, but not necessarily.
Finally, a wait-free data structure has the maximum potential for true concurrent access, without the possibility of busy waits. However, these are very much harder to write than other lock-free data structures, and typically impose an additional performance cost on every access.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: concurrency, threading, multithreading, lock-free, wait-free
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Implementing Dekker's algorithm with Fences
Tuesday, 27 July 2010
Dekker's algorithm is one of the most basic algorithms for mutual exclusion, alongside Peterson's algorithm and Lamport's bakery algorithm. It has the nice property that it only requires load and store operations rather than exchange or test-and-set, but it still requires some level of ordering between the operations. On a weakly-ordered architecture such as PowerPC or SPARC, a correct implementation of Dekker's algorithm thus requires the use of fences or memory barriers in order to ensure correct operation.
The code
For those of you who just want the code: here it is — Dekker's algorithm in C++, with explicit fences.
std::atomic<bool> flag0(false),flag1(false);
std::atomic<int> turn(0);
void p0()
{
flag0.store(true,std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_seq_cst);
while (flag1.load(std::memory_order_relaxed))
{
if (turn.load(std::memory_order_relaxed) != 0)
{
flag0.store(false,std::memory_order_relaxed);
while (turn.load(std::memory_order_relaxed) != 0)
{
}
flag0.store(true,std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_seq_cst);
}
}
std::atomic_thread_fence(std::memory_order_acquire);
// critical section
turn.store(1,std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_release);
flag0.store(false,std::memory_order_relaxed);
}
void p1()
{
flag1.store(true,std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_seq_cst);
while (flag0.load(std::memory_order_relaxed))
{
if (turn.load(std::memory_order_relaxed) != 1)
{
flag1.store(false,std::memory_order_relaxed);
while (turn.load(std::memory_order_relaxed) != 1)
{
}
flag1.store(true,std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_seq_cst);
}
}
std::atomic_thread_fence(std::memory_order_acquire);
// critical section
turn.store(0,std::memory_order_relaxed);
std::atomic_thread_fence(std::memory_order_release);
flag1.store(false,std::memory_order_relaxed);
}
The analysis
If you're like me then you'll be interested in why stuff works, rather than just taking the code. Here is my analysis of the required orderings, and how the fences guarantee those orderings.
Suppose thread 0 and thread 1 enter p0
and p1 respectively at the same time. They both set their
respective flags to true, execute the fence and then read
the other flag at the start of the while loop.
If both threads read false then both will enter the
critical section, and the algorithm doesn't work. It is the job of the
fences to ensure that this doesn't happen.
The fences are marked with memory_order_seq_cst, so either the
fence in p0 is before the fence in p1 in the global ordering of
memory_order_seq_cst operations, or vice-versa. Without
loss of generality, we can assume that the fence in p0
comes before the fence in p1, since the code is
symmetric. The store to flag0 is sequenced before the
fence in p0, and the fence in p1 is
sequenced before the read from flag0. Therefore the
read from flag0 must see the value stored
(true), so p1 will enter
the while loop.
On the other side, there is no such guarantee for the read
from flag1 in p0, so p0 may or
may not enter the while loop. If p0 reads
the value of false for flag1, it will not
enter the while loop, and will instead enter the critical
section, but that is OK since p1 has entered
the while loop.
Though flag0 is not set to false
until p0 has finished the critical section, we need to
ensure that p1 does not see this until the values
modified in the critical section are also visible to p1,
and this is the purpose of the release fence prior to the store
to flag0 and the acquire fence after
the while loop. When p1 reads the
value false from
flag0 in order to exit the while loop, it
must be reading the value store by p0 after the release
fence at the end of the critical section. The acquire fence after the
load guarantees that all the values written before the release fence
prior to the store are visible, which is exactly what we need
here.
If p0 reads true for flag1,
it will enter the while loop rather than the critical
section. Both threads are now looping, so we need a way to ensure
that exactly one of them breaks out. This is the purpose of
the turn variable. Initially, turn is 0,
so p1 will enter the if and
set flag1 to false, whilst p1
will not enter the if. Because p1 set
flag1 to false, eventually p0
will read flag1 as false and exit the
outer while loop to enter the critical section. On the
other hand, p1 is now stuck in the
inner while loop because turn is
0. When p0 exits the critical section it
sets turn to 1. This will eventually be seen
by p1, allowing it to exit the inner while
loop. When the store to
flag0 becomes visible p1 can then exit the
outer while loop too.
If turn had been 1 initially (because p0
was the last thread to enter the critical section) then the inverse
logic would apply, and p0 would enter the inner loop,
allowing p1 to enter the critical section first.
Second time around
If p0 is called a second time whilst p1
is still in the inner loop then we have a similar situation to the
start of the function — p1 may exit the inner
loop and store true in flag1
whilst p0 stores true
in flag0. We therefore need the
second memory_order_seq_cst fence after the store to
the flag in the inner loop. This guarantees that
at least one of the threads will see the flag from the other thread
set when it executes the check in the outer loop. Without this fence
then both threads can read false, and both can enter
the critical section.
Alternatives
You could put the ordering constraints on the loads and stores
themselves rather than using fences. Indeed, the default memory
ordering for atomic operations in C++
is memory_order_seq_cst, so the algorithm would "just
work" with plain loads and stores to atomic variables. However, by
using memory_order_relaxed on the loads and stores we
can add fences to ensure we have exactly the ordering constraints
required.
Posted by Anthony Williams
[/ threading /] permanent link
Tags: concurrency, synchronization, Dekker, fences, cplusplus
Stumble It! ![]() | Submit to Reddit
| Submit to Reddit ![]() | Submit to DZone
| Submit to DZone ![]()
If you liked this post, why not subscribe to the RSS feed ![]() or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
or Follow me on Twitter? You can also subscribe to this blog by email using the form on the left.
Design and Content Copyright © 2005-2026 Just Software Solutions Ltd. All rights reserved. | Privacy Policy